机器学习是什么,有什么用?(新手必看)
何谓机器学习?1959 年,Arthur Samuel 定义机器学习为:计算机在不直接编程的情况下,自动学会如何完成任务。
通过编程,我们直接告诉计算机该怎么完成任务。一旦任务超过编程时考虑的范围,程序将无法保持稳定性,我们称这种方式为编程驱动。
使用编程驱动的方法,也许可以计算出 A 到 B 的最短路径,但却不能直接“指导”计算机如何分类图片,因为我们不可能让计算机涵盖世界上所有图片的特征。相反,基于数据驱动而非编程驱动的方式,让计算机从数据中“学习”规律,进而能够完成某项任务或工作。
举个简单的例子,假设小明的乒乓球技术很好但篮球技术却很差,如果翻译“小明的乒乓球谁也打不过”,通过编程驱动的方式,可以设计一个语法分析树,逐一分析每个中文的词性,根据词性再直译成英文为 No one can beat Xiao Ming in table tennis;“小明的篮球谁也打不过”该怎么翻译呢?通过分析语法来解析句子,再直译,显然得不到想要的翻译结果。
如果采用机器学习方式,事先把小明的篮球和乒乓球等相关数据全部输入计算机中,通过“统计+数据”的方法训练一个决策模型,如下图所示,该模型结合所输入的数据,“学”到小明篮球差这个事实,从而能够正确翻译。
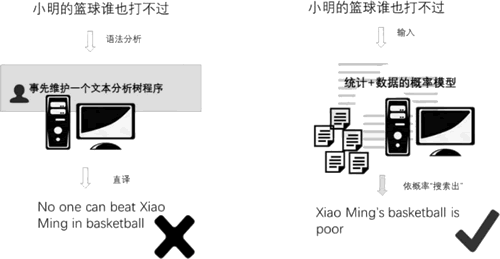
图 1 数据驱动方法与程序维护法在汉语翻译上的区别
可能有人会反驳说,如果知道小明的篮球差,那么在用编程驱动的方法翻译语句时,只要设置一个条件语句不就行了吗?区别就在这里,编程驱动需要让我们知道“小明篮球差”这一点,从而在编程时预防性地增加一个条件语句。而机器学习则不然,它并不需要程序员认识小明,它只需要有关小明的数据即可。
因此,这里给机器学习下一个定义:所谓机器学习,是计算机使用数据驱动的方法,训练出一个令人满意的模型,从而使用模型完成各种需要一定“知识”的任务。
所谓大数据,简单来说就是海量的数据。随着网络普及和 Web 技术的发展,计算机算力飞速提升而存储器价格不断下跌,获取海量的数据已不再是什么难事,数据库技术也使得管理庞大的数据不再困难,大数据是人工智能等相关学科的支撑。
假设小明是一个国际明星,那么可以很容易地获取到与他相关的许多数据。如果小明是一个普通人,因为缺乏相关数据,应用机器学习的方法则变得举步维艰。
数据挖掘(data mining)是从海量的数据中挖掘知识的一项技术,其包括机器学习、统计学习和数据库技术等。
而人工智能更像一门科学,旨在为机器赋予视觉、听觉、触觉和推理等智能。人工智能(AI)不在乎如何实现,而在于能否实现。因此,无论直接编程还是数据驱动,只要能实现机器智能,都可称之为人工智能技术。
如下图所示,人工智能是广义的概念,它与电信、电子、自控和统计学都有联系。数据挖掘是以数据驱动为主,从数据中挖掘知识的技术,是人工智能的一个子集。大数据作为数据驱动方法的支撑,也是人工智能得以迅速发展的支柱。
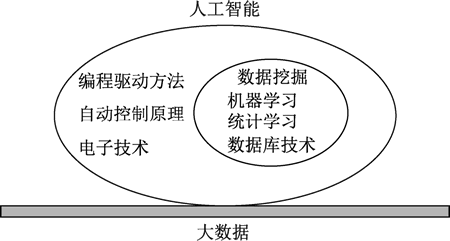
图 2 大数据、人工智能与数据挖掘的关系
机器学习是人工智能的一种计算方法,而深度学习(deep learning)则是以神经网络为主的机器学习方法之一,三者为从属关系,如下图所示。

图 3 人工智能机器学习和深度学习的关系示意
实际上,自机器学习出现以来,其与统计学习之间的关系至今没有定论。有人说“机器学习是大数据时代的统计学”,也有人认为“机器学习即统计学习”,还有人说“机器学习是被鼓吹出来的统计学习”,又“有人认为统计学习是一种小样本的机器学习”。
有学者则认为统计学习与机器学习的侧重点不同,统计学习关注的是模型参数的准确性,对未知数据的预测效果就没有那么重要了;而机器学习具有明确的目标,即提升模型的实用性。
综合各种文献资料,我们总结出统计学习与机器学习的大致区别,如下表所示:
一些看似“高大上”的应用,本质上都属于上述三大问题之一。下面结合具体实例,讲解三大问题的含义。
分类问题区别于聚类问题,它是根据已知的分类来分类的。后者则不然,聚类时通过相似性自动将数据聚合成类。
例如,根据房屋的特征(面积、位置等)来预测其市场价格;根据历史销售数据和市场趋势预测未来的销售额;根据历史天气数据和当前气象条件来预测未来的气温、降水量等,我们称这种输出为数值型变量的问题为回归问题。
例如,我们在清理手机中的垃圾数据时,通常会推荐重复的照片、截图或者看起来非常相似的图片,让用户判断是否需要删除,这就是聚类的应用。
聚类是在没有任何已知信息的前提下,计算机根据数据相似性自主学习,将物体聚为多类的任务。应该说,分类问题是一种监督学习,而聚类则属于无监督学习。
通过编程,我们直接告诉计算机该怎么完成任务。一旦任务超过编程时考虑的范围,程序将无法保持稳定性,我们称这种方式为编程驱动。
使用编程驱动的方法,也许可以计算出 A 到 B 的最短路径,但却不能直接“指导”计算机如何分类图片,因为我们不可能让计算机涵盖世界上所有图片的特征。相反,基于数据驱动而非编程驱动的方式,让计算机从数据中“学习”规律,进而能够完成某项任务或工作。
举个简单的例子,假设小明的乒乓球技术很好但篮球技术却很差,如果翻译“小明的乒乓球谁也打不过”,通过编程驱动的方式,可以设计一个语法分析树,逐一分析每个中文的词性,根据词性再直译成英文为 No one can beat Xiao Ming in table tennis;“小明的篮球谁也打不过”该怎么翻译呢?通过分析语法来解析句子,再直译,显然得不到想要的翻译结果。
如果采用机器学习方式,事先把小明的篮球和乒乓球等相关数据全部输入计算机中,通过“统计+数据”的方法训练一个决策模型,如下图所示,该模型结合所输入的数据,“学”到小明篮球差这个事实,从而能够正确翻译。
图 1 数据驱动方法与程序维护法在汉语翻译上的区别
可能有人会反驳说,如果知道小明的篮球差,那么在用编程驱动的方法翻译语句时,只要设置一个条件语句不就行了吗?区别就在这里,编程驱动需要让我们知道“小明篮球差”这一点,从而在编程时预防性地增加一个条件语句。而机器学习则不然,它并不需要程序员认识小明,它只需要有关小明的数据即可。
因此,这里给机器学习下一个定义:所谓机器学习,是计算机使用数据驱动的方法,训练出一个令人满意的模型,从而使用模型完成各种需要一定“知识”的任务。
机器学习的相关学科
在谈到机器学习时,经常会提及人工智能、大数据、数据挖掘和深度学习等相关概念。所谓大数据,简单来说就是海量的数据。随着网络普及和 Web 技术的发展,计算机算力飞速提升而存储器价格不断下跌,获取海量的数据已不再是什么难事,数据库技术也使得管理庞大的数据不再困难,大数据是人工智能等相关学科的支撑。
假设小明是一个国际明星,那么可以很容易地获取到与他相关的许多数据。如果小明是一个普通人,因为缺乏相关数据,应用机器学习的方法则变得举步维艰。
数据挖掘(data mining)是从海量的数据中挖掘知识的一项技术,其包括机器学习、统计学习和数据库技术等。
而人工智能更像一门科学,旨在为机器赋予视觉、听觉、触觉和推理等智能。人工智能(AI)不在乎如何实现,而在于能否实现。因此,无论直接编程还是数据驱动,只要能实现机器智能,都可称之为人工智能技术。
如下图所示,人工智能是广义的概念,它与电信、电子、自控和统计学都有联系。数据挖掘是以数据驱动为主,从数据中挖掘知识的技术,是人工智能的一个子集。大数据作为数据驱动方法的支撑,也是人工智能得以迅速发展的支柱。
图 2 大数据、人工智能与数据挖掘的关系
机器学习是人工智能的一种计算方法,而深度学习(deep learning)则是以神经网络为主的机器学习方法之一,三者为从属关系,如下图所示。
图 3 人工智能机器学习和深度学习的关系示意
机器学习VS统计学习
同样是基于数据+统计的方法,从数据中寻找知识的技术,机器学习与统计学习有何区别呢?实际上,自机器学习出现以来,其与统计学习之间的关系至今没有定论。有人说“机器学习是大数据时代的统计学”,也有人认为“机器学习即统计学习”,还有人说“机器学习是被鼓吹出来的统计学习”,又“有人认为统计学习是一种小样本的机器学习”。
有学者则认为统计学习与机器学习的侧重点不同,统计学习关注的是模型参数的准确性,对未知数据的预测效果就没有那么重要了;而机器学习具有明确的目标,即提升模型的实用性。
综合各种文献资料,我们总结出统计学习与机器学习的大致区别,如下表所示:
| 区别 | 统计学习 | 机器学习 |
|---|---|---|
| 求解模型参数方面 | 统计学习往往需要根据数据集对模型参数进行区间估计:在给出参数值的同时给出置信区间和相应的置信水平 | 机器学习只需要提供模型参数的点估计,不需要设置显著水平并给定置信区间 |
| 评价模型方面 | 在统计学习中,参数必须经过严格的诊断,如 p 值、R 方等 | 诊断一个机器学习模型,通常是考虑模型在测试集中的拟合优度 |
| 数据集划分方面 | 统计学习不需要对数据进行拆分 | 机器学习至少要将数据集拆分为训练集和测试集 |
| 侧重点方面 | 关注点在于模型参数的正确与否,而非模型解决问题的能力 | 重点关注模型的实用能力和泛化能力 |
机器学习的作用
机器学习主要解决三大问题:- 分类问题,如识别物体、评价事物、对事物进行分类;
- 回归问题,如预测数值;
- 聚类问题,如自动归类等。
一些看似“高大上”的应用,本质上都属于上述三大问题之一。下面结合具体实例,讲解三大问题的含义。
1) 分类问题
分类问题的回答通常是一个离散型的变量。例如,在物体检测中,需要回答有与没有;在评价事物时,将其分为三六九等;在检测人是否患病时,回答是与不是。分类问题区别于聚类问题,它是根据已知的分类来分类的。后者则不然,聚类时通过相似性自动将数据聚合成类。
2) 回归问题
区别于输出离散型结果的分类问题,回归问题是指预测或估算数值型因变量的问题。例如,根据房屋的特征(面积、位置等)来预测其市场价格;根据历史销售数据和市场趋势预测未来的销售额;根据历史天气数据和当前气象条件来预测未来的气温、降水量等,我们称这种输出为数值型变量的问题为回归问题。
3) 聚类问题
同样是划分类别,区别于分类问题,聚类问题在问题之初没有事先给定类别。聚类算法依靠计算机通过计算数据之间的相似性,自动将相近的数据划分为同一类。例如,我们在清理手机中的垃圾数据时,通常会推荐重复的照片、截图或者看起来非常相似的图片,让用户判断是否需要删除,这就是聚类的应用。
聚类是在没有任何已知信息的前提下,计算机根据数据相似性自主学习,将物体聚为多类的任务。应该说,分类问题是一种监督学习,而聚类则属于无监督学习。
 ICP备案:
ICP备案: 公安联网备案:
公安联网备案: