LLM训练和微调详解
LLM 的性能本质上依赖大规模预训练与任务特定微调两个阶段的协同构建:
训练目标设计、数据选择策略、参数调整方式与评估指标体系等因素,共同决定了模型的泛化能力与实际应用表现。
本节将系统阐述 LLM 训练与微调的技术机制与实践要点。
预训练阶段旨在构建具备通用语言理解与生成能力的基础模型,而微调阶段则根据具体任务对模型能力进行针对性的优化与强化。
这种训练策略在保持模型通用性的同时,兼顾任务适配性,是现代大规模语言模型能够跨任务迁移应用的根本机制。
常见的预训练目标包括自回归语言建模和掩码语言建模两类。自回归方法以预测当前 Token 的下一个词为目标,常用于 GPT 系列模型,擅长生成类任务。
掩码语言建模通过对输入文本中的部分 Token 进行掩盖,要求模型恢复原始内容,代表性模型为 BERT,擅长理解类任务。近年来也出现了多目标联合预训练、句子排序、段落预测等复杂策略,用以增强模型对语言层级结构的建模能力。
预训练的数据来源广泛,通常包括网络文本、百科语料、代码库、多语言语料等。数据多样性与覆盖面直接影响模型的泛化能力。为了适应大规模计算资源的需求,预训练过程采用分布式训练框架,如数据并行、模型并行与流水线并行等进行加速,并配合使用学习率预热、损失归一化、梯度裁剪等优化技巧稳定训练过程。
微调策略通常分为两类,分别是全参数微调与参数高效微调:
全参数微调对模型所有参数进行更新,适用于算力充足且任务差异较大的场景;
参数高效微调通过冻结大部分模型参数,仅调整部分权重层,例如使用 Adapter 模块或 LoRA(Low-Rank Adaptation)方法,降低训练成本并提升部署效率。
根据任务类型的不同,微调可分为文本分类、序列标注、问答匹配、对话生成、摘要生成等多种模式。每种任务需要设计不同的输入/输出格式及损失函数,并通过 Prompt 模板、任务指令等方式对输入进行结构化加工,使模型更精准地对接任务目标。在多任务融合场景中,还可采用共享 Encoder、任务特定 Decoder 等架构实现统一训练与推理。
下图展示了 LLM 训练的两阶段路径:
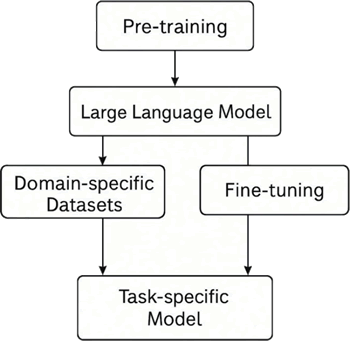
图 1 LLM 训练的两阶段路径
预训练阶段通过自监督方法在海量开放语料上构建通用语言模型,捕捉基础语义与句法规律。预训练模型完成后可沿两种方式继续优化:
最终输出的模型具备领域适应性和任务指向性,可直接部署于实际应用场景。
为系统性理解 LLM 在预训练与微调阶段所采用的不同策略、方法及其技术特点,可通过结构化对比方式呈现两者在目标设定、数据需求、计算资源及适用场景等方面的差异。下表对预训练与微调阶段的策略与方法进行了对比。
表中清晰展示了 LLM 训练中两个关键阶段的功能定位与技术策略差异。理解这些差异,有助于合理设计上下文协议、任务调度逻辑以及输入提示结构,使模型在 MCP 系统中获得稳定、可控的运行表现。
在协议化上下文控制场景下,如 MCP 系统,预训练所构建的语义表示能力与微调时引入的语义边界设定共同作用,支持 Slot 语义分隔、工具调用意图识别及系统指令响应能力的稳定构建。预训练与微调策略的选择与执行,直接影响大模型在实际系统中的表现质量与可控性。
预训练阶段依赖广覆盖、多类型的开放语料构建通用语言模型,微调阶段则侧重在任务相关性与标签质量之间取得平衡,形成针对性的能力微调。
数据集的选择与处理方式,不仅是模型能力上限的决定因素,也深刻影响其后续在多任务、多语境环境下的表现稳定性。
语料清洗是预训练数据构建的重要环节,涉及非自然语言内容过滤、乱码剔除、数据去重、文本去标识化处理等操作,需避免数据污染、任务泄漏和生成伪学习现象,以提升语言建模的泛化能力与稳健性。针对多语言模型,还需引入平衡机制,防止少数高资源语言主导模型参数分布,确保语言间的语义均衡。
高质量微调数据需具备语义明确、任务目标清晰、格式一致性强等特征,方能有效引导模型参数朝任务方向优化。数据采样策略(如过采样、下采样、类别均衡)在类别不均或数据稀疏的场景下尤为关键,影响模型对低频模式的学习能力。
近年来,指令微调数据集成为 LLM 能力压缩与泛化的重要来源。例如 Self-Instruct、OpenAssistant、Alpaca 等数据集通过人工或模型生成方式构建多任务指令集,引导模型适应复杂 Prompt 指令结构与多轮语义交互。此类数据不仅提升了模型对自然语言任务指令的响应能力,也为协议化交互结构的支持奠定基础。
Tokenization 策略决定了文本的分词粒度与表示能力,不同模型可能使用 BPE、SentencePiece 或 Unigram 等编码方式。在上下文协议应用中,还需处理 Slot 间的边界标记、前缀注入与位置对齐等问题,确保语义层次清晰表达。
此外,Token 预算控制也是实际部署中的关键问题,尤其在固定窗口长度模型中,数据预处理阶段需进行句子裁剪、上下文压缩与重要性排序等操作,以最大限度保留核心语义信息。在多任务训练或多轮交互任务中,还需设计合理的上下文滚动机制与历史融合策略。
总的来说,LLM 的预训练依赖高质量大规模语料,其语料构成直接影响模型的语义广度、知识密度以及跨领域泛化能力。不同模型依据其设计目标与语料获取策略,在数据来源、语言覆盖、清洗标准等方面做出不同取舍。
下表整理了当前主流 LLM 在预训练阶段使用的数据集构成,便于从工程实践角度理解数据选择对模型能力形成的影响。
从表中可以看出,预训练数据的选择呈现出多元融合趋势,模型性能越来越依赖数据质量、语言多样性与任务结构的覆盖度。同时,中文模型与英文模型在语料获取路径与清洗方式上差异明显,亦需在实际构建协议化交互系统(如 MCP)时予以考虑,以确保上下文输入的语义匹配与语言风格的一致性。
数据集不仅是语言模型的训练基础,也决定了模型对 MCP 中 Slot 结构、工具响应、系统控制指令等输入形式的适应能力。构建适配于协议驱动范式的数据体系,是提升 MCP 系统响应稳定性与语义精度的前提条件。
评估不仅用于衡量模型是否学习到了目标任务的语义能力,也用于诊断结构设计、训练策略、数据分布等因素对模型行为的影响。
性能优化则将评估结果反馈到训练与部署环节,通过算法与系统层的手段提升模型的响应速度、资源利用效率与语义表现质量。
在多任务预训练与指令微调阶段,还可引入多轮对话一致性、Tool Call 正确性、语义覆盖度等协议相关指标,以支持复杂任务下的语义跟踪与行为控制。
在 MCP 框架中,Slot 注入的正确性与上下文对齐度是重要的评估对象。需衡量模型对不同类型 Slot(System/User/Tool 等)的语义区分能力,以及模型在不同 Slot 信息交错输入时的语义融合与输出稳定性。对于工具调用类任务,还需评估模型对外部响应的调用时机与参数理解精度。
在协议增强模型中,需构建结构化 Prompt 评估集合,对不同 Slot 结构、任务组合进行组合测试,验证模型对协议结构的泛化能力。
在线评估则更贴近实际使用场景,通常与日志追踪、用户交互反馈系统集成,通过指标采样、人工评分、A/B测试等方式不断获取模型行为数据。可结合上下文链路日志与响应行为日志,构建行为分析系统,对模型生成内容中的冗余性、幻觉率、错误调用等进行实时监控,从而形成动态优化闭环。
在算法层面,结构剪枝、权重蒸馏、量化压缩等方法被广泛应用于推理加速,低秩适配(LoRA)、提示调优(Prompt Tuning)等轻量策略则被用于在不影响主干参数的前提下快速适配新任务。训练过程中的梯度精度控制、动态批量调度、混合精度训练等技术也显著提高了大模型训练的稳定性与效率。
在系统层,缓存机制、KV Cache 优化、Token 流式输出、模型分片与并行部署均是实际应用中不可或缺的性能优化手段。结合协议场景中的上下文模式特点,还可通过 Slot 复用、Prompt 模板压缩与 Context Trimming 等方法对输入序列进行高效编排,降低 Token 消耗,提升整体响应速度。
评估与优化构成了大模型开发闭环中的核心环节,是确保 MCP 驱动系统具备稳定交互、可控语义与工程可用性的基础保障。系统性的评估策略与精细化的优化技术,将持续推动大模型在复杂任务场景中的实际表现能力。
- 预训练阶段通过自监督学习从海量语料中捕获通用语言规律;
- 微调阶段则通过少量高质量标注数据实现模型能力的定向强化。
训练目标设计、数据选择策略、参数调整方式与评估指标体系等因素,共同决定了模型的泛化能力与实际应用表现。
本节将系统阐述 LLM 训练与微调的技术机制与实践要点。
LLM预训练与微调的策略和方法
LLM 的构建依赖两阶段训练范式,分别是预训练和微调。预训练阶段旨在构建具备通用语言理解与生成能力的基础模型,而微调阶段则根据具体任务对模型能力进行针对性的优化与强化。
这种训练策略在保持模型通用性的同时,兼顾任务适配性,是现代大规模语言模型能够跨任务迁移应用的根本机制。
1) 预训练目标与策略
预训练通常采用自监督学习方法,通过构造预测任务在大规模未标注文本上训练模型。常见的预训练目标包括自回归语言建模和掩码语言建模两类。自回归方法以预测当前 Token 的下一个词为目标,常用于 GPT 系列模型,擅长生成类任务。
掩码语言建模通过对输入文本中的部分 Token 进行掩盖,要求模型恢复原始内容,代表性模型为 BERT,擅长理解类任务。近年来也出现了多目标联合预训练、句子排序、段落预测等复杂策略,用以增强模型对语言层级结构的建模能力。
预训练的数据来源广泛,通常包括网络文本、百科语料、代码库、多语言语料等。数据多样性与覆盖面直接影响模型的泛化能力。为了适应大规模计算资源的需求,预训练过程采用分布式训练框架,如数据并行、模型并行与流水线并行等进行加速,并配合使用学习率预热、损失归一化、梯度裁剪等优化技巧稳定训练过程。
2) 微调方法与应用模式
微调阶段在少量带标签的任务数据上继续训练模型,使其在保持通用能力的基础上,更好地对接具体应用场景。微调策略通常分为两类,分别是全参数微调与参数高效微调:
全参数微调对模型所有参数进行更新,适用于算力充足且任务差异较大的场景;
参数高效微调通过冻结大部分模型参数,仅调整部分权重层,例如使用 Adapter 模块或 LoRA(Low-Rank Adaptation)方法,降低训练成本并提升部署效率。
根据任务类型的不同,微调可分为文本分类、序列标注、问答匹配、对话生成、摘要生成等多种模式。每种任务需要设计不同的输入/输出格式及损失函数,并通过 Prompt 模板、任务指令等方式对输入进行结构化加工,使模型更精准地对接任务目标。在多任务融合场景中,还可采用共享 Encoder、任务特定 Decoder 等架构实现统一训练与推理。
3) 预训练与微调的协同作用
预训练提供语言知识的通用表示能力,是微调效果的基础保障。微调通过上下文注入、标签引导或提示工程实现模型能力的定向释放。两者的协同效应使 LLM 能够在极少标注数据的条件下,完成过去依赖复杂特征工程的任务,为当前语言模型的工业化落地提供了强大支撑。下图展示了 LLM 训练的两阶段路径:
图 1 LLM 训练的两阶段路径
预训练阶段通过自监督方法在海量开放语料上构建通用语言模型,捕捉基础语义与句法规律。预训练模型完成后可沿两种方式继续优化:
- 其一是基于特定领域数据进行补充训练,使模型在特定语料分布下提升表现;
- 其二是使用任务标注数据进行微调,通过监督学习调整模型参数以适应分类、问答、摘要等具体任务。
最终输出的模型具备领域适应性和任务指向性,可直接部署于实际应用场景。
为系统性理解 LLM 在预训练与微调阶段所采用的不同策略、方法及其技术特点,可通过结构化对比方式呈现两者在目标设定、数据需求、计算资源及适用场景等方面的差异。下表对预训练与微调阶段的策略与方法进行了对比。
| 对比维度 | 预训练阶段 | 微调阶段 |
|---|---|---|
| 目标类型 | 通用语言建模(如预测下一个词、掩码恢复) | 任务定向优化(如分类、问答、摘要) |
| 数据来源 | 大规模未标注开放语料 | 少量高质量标注数据或结构化任务数据 |
| 学习方式 | 自监督学习 | 监督学习或指令学习 |
| 参数更新范围 | 全参数更新 | 可选:全参数或参数高效微调(如 LoRA、Adapter) |
| 架构使用 | 编码器、解码器或其变体(BERT、GPT 等) | 通常在预训练结构基础上微调特定层 |
| 应用适配性 | 提供统一语言表示能力,支持多任务泛化 | 强化某一具体任务的表现能力 |
| 计算资源消耗 | 极高,需长时间分布式训练 | 资源相对可控,可在中等规模设备上完成 |
| 输入结构 | 自然文本,可能不包含明确任务指令 | 结构化输入(如 Prompt 模板、任务指令) |
| 示例需求 | 无须标注数据,依赖大语料规模与覆盖面 | 需人工标注或通过模型生成数据,强调质量与格式一致性 |
| 语义控制能力 | 低,模型行为不可控 | 高,可通过 Prompt、指令等方式引导生成结果 |
表中清晰展示了 LLM 训练中两个关键阶段的功能定位与技术策略差异。理解这些差异,有助于合理设计上下文协议、任务调度逻辑以及输入提示结构,使模型在 MCP 系统中获得稳定、可控的运行表现。
在协议化上下文控制场景下,如 MCP 系统,预训练所构建的语义表示能力与微调时引入的语义边界设定共同作用,支持 Slot 语义分隔、工具调用意图识别及系统指令响应能力的稳定构建。预训练与微调策略的选择与执行,直接影响大模型在实际系统中的表现质量与可控性。
数据集的选择与处理
LLM 训练的核心资源之一是大规模高质量语料。数据集的构成直接影响模型的语言覆盖能力、知识储备、风格适应性以及领域泛化能力。预训练阶段依赖广覆盖、多类型的开放语料构建通用语言模型,微调阶段则侧重在任务相关性与标签质量之间取得平衡,形成针对性的能力微调。
数据集的选择与处理方式,不仅是模型能力上限的决定因素,也深刻影响其后续在多任务、多语境环境下的表现稳定性。
1) 预训练语料的来源与构建
预训练阶段的数据集需具备足够规模与多样性,以支持模型学习语言的统计特征与结构规律。通用语料来源包括开源百科(如维基百科)、开放论坛(如 Reddit、StackExchange)、新闻媒体、图书馆数字资源以及开源代码仓库。部分高质量数据集如 The Pile、C4、BooksCorpus、Common Crawl 等已成为主流大模型的预训练基础。语料清洗是预训练数据构建的重要环节,涉及非自然语言内容过滤、乱码剔除、数据去重、文本去标识化处理等操作,需避免数据污染、任务泄漏和生成伪学习现象,以提升语言建模的泛化能力与稳健性。针对多语言模型,还需引入平衡机制,防止少数高资源语言主导模型参数分布,确保语言间的语义均衡。
2) 微调数据的组织与标注
微调阶段的数据集往往源于人工标注或任务系统日志提取,常见形式包括分类标签、序列标注、问答对、摘要段、对话轮次等。高质量微调数据需具备语义明确、任务目标清晰、格式一致性强等特征,方能有效引导模型参数朝任务方向优化。数据采样策略(如过采样、下采样、类别均衡)在类别不均或数据稀疏的场景下尤为关键,影响模型对低频模式的学习能力。
近年来,指令微调数据集成为 LLM 能力压缩与泛化的重要来源。例如 Self-Instruct、OpenAssistant、Alpaca 等数据集通过人工或模型生成方式构建多任务指令集,引导模型适应复杂 Prompt 指令结构与多轮语义交互。此类数据不仅提升了模型对自然语言任务指令的响应能力,也为协议化交互结构的支持奠定基础。
3) 数据处理的格式标准与Token控制
模型训练前的数据需转化为标准输入格式,通常包含 Token 序列、Segment 标识、注意力掩码等。Tokenization 策略决定了文本的分词粒度与表示能力,不同模型可能使用 BPE、SentencePiece 或 Unigram 等编码方式。在上下文协议应用中,还需处理 Slot 间的边界标记、前缀注入与位置对齐等问题,确保语义层次清晰表达。
此外,Token 预算控制也是实际部署中的关键问题,尤其在固定窗口长度模型中,数据预处理阶段需进行句子裁剪、上下文压缩与重要性排序等操作,以最大限度保留核心语义信息。在多任务训练或多轮交互任务中,还需设计合理的上下文滚动机制与历史融合策略。
总的来说,LLM 的预训练依赖高质量大规模语料,其语料构成直接影响模型的语义广度、知识密度以及跨领域泛化能力。不同模型依据其设计目标与语料获取策略,在数据来源、语言覆盖、清洗标准等方面做出不同取舍。
下表整理了当前主流 LLM 在预训练阶段使用的数据集构成,便于从工程实践角度理解数据选择对模型能力形成的影响。
| 模型名称 | 主要数据集来源与组成 | 数据总量规模(粗略估计) |
|---|---|---|
| GPT-3 | Common Crawl、Books1/2、Wikipedia、WebText、Open WebText 等 | 3000亿Token |
| GPT-4(未完全公开) | 基于 GPT-3 数据扩展,新增高质量合成数据与人类反馈样本 | 数万亿 Token(推测) |
| LLaMA 2 | Common Crawl、C4、GitHub、Wikipedia、Books、ArXiv等 | LLaMA2-13B:1万亿Token |
| DeepSeek-V2 | 中文网页、维基百科、新闻、新浪微博、代码等 | 2 万亿 Token |
| Mistral | The Pile、RefinedWeb、Books、StackExchange、HackerNews等 | 1.4 万亿 Token |
| Claude (Anthropic) | 高比例人类反馈训练数据、网页内容、对话语料 | 数万亿 Token(推测) |
| ChatGLM3 | 中文互联网页面、百科、新闻、问答语料、GitHub 代码等 | 数千亿 Token |
| PaLM 2 | C4、Books、Wikipedia、科学语料(PubMed)、对话语料等 | 3.6 万亿 Token |
| Falcon | RefinedWeb、Books、Dialogues、Code、Multilingual Web数据 | 1.5 万亿 Token |
从表中可以看出,预训练数据的选择呈现出多元融合趋势,模型性能越来越依赖数据质量、语言多样性与任务结构的覆盖度。同时,中文模型与英文模型在语料获取路径与清洗方式上差异明显,亦需在实际构建协议化交互系统(如 MCP)时予以考虑,以确保上下文输入的语义匹配与语言风格的一致性。
数据集不仅是语言模型的训练基础,也决定了模型对 MCP 中 Slot 结构、工具响应、系统控制指令等输入形式的适应能力。构建适配于协议驱动范式的数据体系,是提升 MCP 系统响应稳定性与语义精度的前提条件。
模型评估与性能优化
LLM 的评估与性能优化体系直接决定其在实际应用中的可靠性、可控性与部署价值。评估不仅用于衡量模型是否学习到了目标任务的语义能力,也用于诊断结构设计、训练策略、数据分布等因素对模型行为的影响。
性能优化则将评估结果反馈到训练与部署环节,通过算法与系统层的手段提升模型的响应速度、资源利用效率与语义表现质量。
1) 评估维度与指标体系
语言模型的评估可以分为通用能力评估与任务特定评估两个层面。通用能力评估主要包括语言流畅性、上下文一致性、事实准确性、逻辑推理能力等维度,常用指标包括困惑度、BLEU、ROUGE、Exact Match 等。在多任务预训练与指令微调阶段,还可引入多轮对话一致性、Tool Call 正确性、语义覆盖度等协议相关指标,以支持复杂任务下的语义跟踪与行为控制。
在 MCP 框架中,Slot 注入的正确性与上下文对齐度是重要的评估对象。需衡量模型对不同类型 Slot(System/User/Tool 等)的语义区分能力,以及模型在不同 Slot 信息交错输入时的语义融合与输出稳定性。对于工具调用类任务,还需评估模型对外部响应的调用时机与参数理解精度。
2) 离线评估与在线反馈机制
离线评估适用于训练阶段与大规模模型选择阶段。通过固定测试集进行批量推理,可在标准任务如文本分类、摘要生成、问答系统等场景中获得稳定指标。在协议增强模型中,需构建结构化 Prompt 评估集合,对不同 Slot 结构、任务组合进行组合测试,验证模型对协议结构的泛化能力。
在线评估则更贴近实际使用场景,通常与日志追踪、用户交互反馈系统集成,通过指标采样、人工评分、A/B测试等方式不断获取模型行为数据。可结合上下文链路日志与响应行为日志,构建行为分析系统,对模型生成内容中的冗余性、幻觉率、错误调用等进行实时监控,从而形成动态优化闭环。
3) 性能优化策略
优化语言模型性能需从算法结构、训练策略与系统实现三方面协同推进。在算法层面,结构剪枝、权重蒸馏、量化压缩等方法被广泛应用于推理加速,低秩适配(LoRA)、提示调优(Prompt Tuning)等轻量策略则被用于在不影响主干参数的前提下快速适配新任务。训练过程中的梯度精度控制、动态批量调度、混合精度训练等技术也显著提高了大模型训练的稳定性与效率。
在系统层,缓存机制、KV Cache 优化、Token 流式输出、模型分片与并行部署均是实际应用中不可或缺的性能优化手段。结合协议场景中的上下文模式特点,还可通过 Slot 复用、Prompt 模板压缩与 Context Trimming 等方法对输入序列进行高效编排,降低 Token 消耗,提升整体响应速度。
评估与优化构成了大模型开发闭环中的核心环节,是确保 MCP 驱动系统具备稳定交互、可控语义与工程可用性的基础保障。系统性的评估策略与精细化的优化技术,将持续推动大模型在复杂任务场景中的实际表现能力。