机器学习的分类有哪些?
机器学习旨在回答分类、聚类和回归的问题。通过机器学习模型的学习方式,可以将机器学习分为监督学习、无监督学习和强化学习等,我们着重讨论监督学习和无监督学习。
下面简要介绍这几种学习方式的定义与区别。
例如鸢尾花的识别问题。首先人们“告诉”计算机,具有某些特征(如颜色、花瓣的形状等)的鸢尾花属于某个类。然后计算机从这些已归好类的数据集中学习知识,从而能够在无人指示的情况下自动判断鸢尾花的类别。
再如股市行情的预测问题,我们将历史的股价数据、相应时间、公司当时的经营状况等作为输入数据让计算机学习。而后计算机能够自动根据时间、经营状况等估算出股价。
综上所述,在监督学习中,输入数据都是带有“参考答案”的,如下图所示,并且就像老师教导学生一样,实际输出通过影响误差,从而动态地调整模型参数,以降低下一次输出的误差。基于这一点,监督学习也被称为导师制学习。
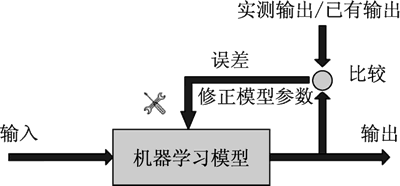
图 1 监督学习流程
如下图所示,通过总结输入特征之间的相似性,从而将输入进行归类。

图 2 无监督学习流程
实际上,聚类正是一种无监督学习。在聚类问题中,人们并没有“告诉”计算机这样划分类别是错误的,计算机往往是根据数据特征的相似性自主学习。有时候,无监督学习可以取到意想不到的效果。
无监督学习经常被用在数据预处理中。例如输入参数过多的情况下,通过聚类能够将相似的参数归为一类,这样就可以减少参数的个数。
无监督学习大致可以用图 2 来描述,其被广泛应用于以下几个方面:
强化学习的过程可以看成一个“试错”的过程,它的反馈信号来源于与环境的交互。例如在 AI 棋手的训练过程中,计算机通过与各种棋手对弈,从零开始学习并尝试各种下棋方法。假如某种方法取得胜利,那么计算机就会记住这种方法是有利的。相反,如果输了,计算机也会记住这种方法是不利于取胜的。
在上述例子中,与棋手对弈的胜负就是反馈信号。在一些文献里,反馈信号通常被称为回报(reward)。如果环境对计算机的输出的反馈是正面的,则机器学习模型会得到鼓励。相反,如果反馈为负面的,则模型会得到惩罚。
因此,强化学习的过程实际上是追求高回报、趋利避害的过程,如下图所示。
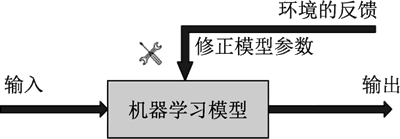
图 3 强化学习流程
再举一个例子,强化学习就好比饲养宠物。如果爱犬做出主人不喜欢的举动,如吃来路不明的食物、与其他狗狗打架、任意狂吠等,便会受到主人的苛责。当狗狗的行为令主人满意时,如主动逗小主人开心、看家等,主人可能就会给狗狗奖励一根肉骨头作为回报。这样久而久之,在与主人的“交互”中,狗狗便知道了如何做能够得到吃的。
强化学习通常应用在以下几个方面:
下面简要介绍这几种学习方式的定义与区别。
监督学习
以邮件过滤为例,在训练模型的过程中,我们需要输入一些已经归好类的邮件作为训练集。如果计算机得出的结论与当前分类不符,则要调整分类器的参数,直到误差在允许范围之内,并通过测试集的诊断为止。之后,计算机便可自动在无人干预的情况下完成邮件的过滤。例如鸢尾花的识别问题。首先人们“告诉”计算机,具有某些特征(如颜色、花瓣的形状等)的鸢尾花属于某个类。然后计算机从这些已归好类的数据集中学习知识,从而能够在无人指示的情况下自动判断鸢尾花的类别。
再如股市行情的预测问题,我们将历史的股价数据、相应时间、公司当时的经营状况等作为输入数据让计算机学习。而后计算机能够自动根据时间、经营状况等估算出股价。
综上所述,在监督学习中,输入数据都是带有“参考答案”的,如下图所示,并且就像老师教导学生一样,实际输出通过影响误差,从而动态地调整模型参数,以降低下一次输出的误差。基于这一点,监督学习也被称为导师制学习。
图 1 监督学习流程
无监督学习
回顾聚类问题,假如现在有一堆图片需要整理,图片里有动物,有风景。人类可以轻而易举地将它们分为两类。而计算机则不然,它会提取图片的轮廓,然后将轮廓相似的图片挑选出来,并据此将图片聚类(当然实际上不可能这么简单)。如下图所示,通过总结输入特征之间的相似性,从而将输入进行归类。
图 2 无监督学习流程
实际上,聚类正是一种无监督学习。在聚类问题中,人们并没有“告诉”计算机这样划分类别是错误的,计算机往往是根据数据特征的相似性自主学习。有时候,无监督学习可以取到意想不到的效果。
无监督学习经常被用在数据预处理中。例如输入参数过多的情况下,通过聚类能够将相似的参数归为一类,这样就可以减少参数的个数。
无监督学习大致可以用图 2 来描述,其被广泛应用于以下几个方面:
- 聚类问题;
- 参数压缩(变多输入为少输入或单输入);
- 异常检验(查找异常数据的检验方法)。
强化学习
不同于无监督学习,强化学习需要一定的反馈信息。同样区别于监督学习,该反馈信号并不是实际值与预测值的误差。强化学习的过程可以看成一个“试错”的过程,它的反馈信号来源于与环境的交互。例如在 AI 棋手的训练过程中,计算机通过与各种棋手对弈,从零开始学习并尝试各种下棋方法。假如某种方法取得胜利,那么计算机就会记住这种方法是有利的。相反,如果输了,计算机也会记住这种方法是不利于取胜的。
在上述例子中,与棋手对弈的胜负就是反馈信号。在一些文献里,反馈信号通常被称为回报(reward)。如果环境对计算机的输出的反馈是正面的,则机器学习模型会得到鼓励。相反,如果反馈为负面的,则模型会得到惩罚。
因此,强化学习的过程实际上是追求高回报、趋利避害的过程,如下图所示。
图 3 强化学习流程
再举一个例子,强化学习就好比饲养宠物。如果爱犬做出主人不喜欢的举动,如吃来路不明的食物、与其他狗狗打架、任意狂吠等,便会受到主人的苛责。当狗狗的行为令主人满意时,如主动逗小主人开心、看家等,主人可能就会给狗狗奖励一根肉骨头作为回报。这样久而久之,在与主人的“交互”中,狗狗便知道了如何做能够得到吃的。
强化学习通常应用在以下几个方面:
- 机器人控制;
- 游戏 AI,如 AlphaGo、机器人世界杯等;
- 无人机、无人汽车的自动驾驶等。
其他
机器学习主要分为前面所讲的三大类,除此之外,还有如下几种分类:- 多任务学习:同时学习多个相关的任务,以提升模型的性能。通过信息共享,针对某个任务的学习可以通过在另外多个任务的学习中获益。
- 半监督学习:在实际应用中,自带“标准答案”的数据往往比较缺乏。例如,在对网页进行分类时,要获取已经分好类的网页,需要花费大量的人力浏览整个网页,然后由专家再进行人工分类,在大数据时代,这种做法太落后了,因此需要在监督学习和无监督学习中达到一个平衡。通常的做法是假设输入与输出之间存在概率上的依赖。
- 实时学习:一般应用在高度动态的任务中。在这个过程中,模型不断地训练,其数据集是通过传感器等设备实时获取的。最典型的例子是自动驾驶技术,在路况千变万化的情况下,仅依靠过去的数据是不切实际的。
 ICP备案:
ICP备案: 公安联网备案:
公安联网备案: