引用是什么,C++中的引用(非常详细,附带实例)
在现实世界中,每个人通常都有好几个称呼,例如:
虽然这些称呼各不相同,但实际上指的是同一个人。
在 C++ 的世界中,也有类似的现象。一个变量除定义时所用到的变量名外,为了便于使用,还可能有多个名字。虽然这些名字各不相同,但实际上指的是同一个变量、同一个数据,通过这些名字,我们都可以访问这个变量。
在现实世界中的多个称呼被称为绰号,而变量在 C++ 世界中的多个名字则被更专业地称为“引用”。
引用的本质就是变量的别名,通俗地说,就是变量的绰号。对变量的引用进行的任何操作,实际上就是对变量本身的操作,就像不管是叫你的小名,还是叫你的绰号,都是在叫你这个人。
在 C++ 中,为某个变量定义引用的语法格式如下:
例如,定义一个整型变量的引用:
建立引用和变量的关联后,任何对引用 nRef 的操作都相当于对变量 nValue 的操作。例如:
这里需要注意的是,引用在定义时必须初始化,将其与某个变量关联起来,否则会产生编译错误。这就像给一个人取绰号,只有这个人存在时,我们才能给他取绰号。我们不可能先把绰号取好,再找到这个绰号所指向的人。
大家可能已经注意到,前面介绍的指针与引用有一些相似之处:它们就像一对孪生兄弟,都是某个变量的指代,都能以一种间接的方式访问它们所指代的变量。虽然是它们很像,但仍然存在一些细微的差别。那么,指针和引用的区别在哪里呢?
我们可以在定义指针时进行初始化,也可以在定义完成后的任何合适时机完成初始化。正是因为指针没有初始化的强制要求,这往往会使我们可能错误地使用尚未初始化的指针,从而产生严重的错误。
例如:
例如:
引用的作用与指针相似,它们都是数据的某种指代。在函数间传递数据时,传递数据的引用要比传递数据本身轻松得多,但效果完全一样。因此,引用的主要应用是在函数间传递参数和返回值。
同样值得注意的是,与指针一样,我们不能将函数内局部变量的引用作为返回值返回。例如:
学完 C++ 引用之后,我们就掌握了以下三种传递函数参数和返回值的方式:
传递函数参数和返回值的方式这么多,选择哪种方式最合适?不同的传递方式有什么区别?在具体应用中应如何选择?
下面的例子将比较这三种在函数间传递数据的方式,帮助我们理解如何做出最佳选择:
1) 在函数 FuncByValue() 中,形式参数 x 只是外部实际参数 n 的一份拷贝。函数内部对 x 的运算不能改变函数外部 n 的值,所以输出的 n 值仍然为 0,与初始值相同。
2) 在函数 FuncByPointer() 中,指针 p 指向外部变量 n,在函数内部改变指针 p 所指向的数据值,实际上就是改变函数外部变量 n 的值,所以输出的 n 值为 1。
3) 在函数 FuncByRef() 中,引用 r 与函数外部变量 n 相关联,它们实际上是同一个数据。在函数内部改变 r 的值,同样也会修改函数外部 n 的值,因此最终输出的 n 值为 2。
对比以上这三种传递参数的方式,可以发现:
综上所述,在传递小体积的参数时,例如某个 int 类型的数据,如果只需传入数据,则选择传值方式;如果需要同时传入和传出数据,则选择传引用方式。在传递大体积的参数时,例如大型对象,优先选择传引用方式。
三种传递参数的方式如下图所示。
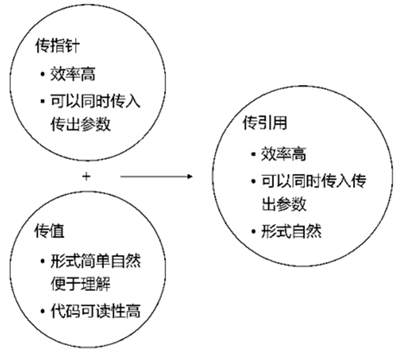
图 1 优先选择传引用
- 长栓:妈妈叫的小名;
- 王君鹏:户口本上的大名;
- 鹏程万里:网上自己取的昵称;
- 胖子:朋友给取的绰号。
虽然这些称呼各不相同,但实际上指的是同一个人。
在 C++ 的世界中,也有类似的现象。一个变量除定义时所用到的变量名外,为了便于使用,还可能有多个名字。虽然这些名字各不相同,但实际上指的是同一个变量、同一个数据,通过这些名字,我们都可以访问这个变量。
在现实世界中的多个称呼被称为绰号,而变量在 C++ 世界中的多个名字则被更专业地称为“引用”。
引用的本质就是变量的别名,通俗地说,就是变量的绰号。对变量的引用进行的任何操作,实际上就是对变量本身的操作,就像不管是叫你的小名,还是叫你的绰号,都是在叫你这个人。
在 C++ 中,为某个变量定义引用的语法格式如下:
数据类型& 引用名 = 变量名;
- 数据类型与要引用的变量的数据类型相同;
- “&”符号表示定义的是一个引用;
- 引用名是变量的第二个名字;
- 变量名是这个引用所要关联的变量本身。
例如,定义一个整型变量的引用:
// 首先定义一个整型变量 int nValue = 1; // 定义一个整型引用 nRef 并将它与整型变量 nValue 关联起来 int& nRef = nValue;这样,就定义了 nRef 是变量 nValue 的引用。
建立引用和变量的关联后,任何对引用 nRef 的操作都相当于对变量 nValue 的操作。例如:
// 通过变量直接修改变量的值 nValue = 1; cout << "通过变量直接修改后, " << endl; cout << "变量的值为" << nValue << endl; cout << "引用的值为" << nRef << endl; // 通过引用修改变量的值 nRef = 2; cout << "通过引用间接修改后, " << endl; cout << "变量的值为" << nValue << endl; cout << "引用的值为" << nRef << endl;程序编译运行后,输出结果如下:
通过变量直接修改后,
变量的值为 1
引用的值为 1
通过引用间接修改后,
变量的值为 2
引用的值为 2
这里需要注意的是,引用在定义时必须初始化,将其与某个变量关联起来,否则会产生编译错误。这就像给一个人取绰号,只有这个人存在时,我们才能给他取绰号。我们不可能先把绰号取好,再找到这个绰号所指向的人。
大家可能已经注意到,前面介绍的指针与引用有一些相似之处:它们就像一对孪生兄弟,都是某个变量的指代,都能以一种间接的方式访问它们所指代的变量。虽然是它们很像,但仍然存在一些细微的差别。那么,指针和引用的区别在哪里呢?
C++引用和指针的区别
1) 初始化的要求不同
引用在定义时必须初始化,而指针则没有这一强制要求。我们可以在定义指针时进行初始化,也可以在定义完成后的任何合适时机完成初始化。正是因为指针没有初始化的强制要求,这往往会使我们可能错误地使用尚未初始化的指针,从而产生严重的错误。
例如:
int x = 0; int* pInt; // 指针在定义时可以不进行初始化,这时它指向一个随机的地址 *pInt = 1; // 使用尚未初始化的指针可能会导致严重的错误 pInt = &x; // 在合适的时机完成指针的初始化 int& rInt = x; // 引用在定义时必须初始化,rInt 是变量 x 的引用
2) 与变量关联的紧密性不同
引用只是变量的别名,不可能存在空的引用,也就是说引用必须与某个合法的、事先存在的变量关联。而指针则可以为空指针(nullptr),不与任何变量建立关联。3) 对重新关联的要求不同
引用一旦被初始化,与某个变量建立了关联,就不能再改变这种引用关系。引用与它所关联的变量之间的关系是从一而终、固定不变的。而指针则可以随时改变所指向的变量。例如:
// 定义另一个整型变量 int y = 1; // 这条语句不是改变 rInt 关联的变量将其关联到 y // 而是对其进行赋值,此时引用 rInt 和变量 x 的值都是 1 rInt = y; // 重新改变指针 pInt 所指向的变量,从 x 变为 y pInt = &y;
C++引用的应用场景
取绰号的目的是什么?没错,是为了让别人称呼起来更加方便。引用是变量的绰号,它的作用也是为了让所关联的变量使用起来更加方便。在进行普通计算时,通常是直接使用变量,无须引用出场。但是,当变量作为函数参数或者返回值,尤其是一些“大腕”数据(大体积数据),需要在函数间进行频繁传递时,引用就非常有用了。引用的作用与指针相似,它们都是数据的某种指代。在函数间传递数据时,传递数据的引用要比传递数据本身轻松得多,但效果完全一样。因此,引用的主要应用是在函数间传递参数和返回值。
同样值得注意的是,与指针一样,我们不能将函数内局部变量的引用作为返回值返回。例如:
// 给整型数加 1
// 利用整型引用作为函数参数
void Increase(int& nVal)
{
nVal += 1;
}
int nInt = 1;
Increase(nInt); // 变量 nInt 的值变为 2
这里利用了一个整型引用作为 Increase() 函数的形式参数。当用一个整型变量作为实际参数调用它时,实际上是用这个整型变量对引用参数进行初始化,让两者建立关联。这样,在函数内部对引用参数的操作就相当于操作实际参数变量本身,实现了函数数据的传入和传出。学完 C++ 引用之后,我们就掌握了以下三种传递函数参数和返回值的方式:
- 传值:将实际参数的值复制给形式参数,完成参数的传递;
- 传指针:将指向需要传递的数据的指针作为参数进行传递;
- 传引用:将需要传递的数据的引用作为参数进行传递。
传递函数参数和返回值的方式这么多,选择哪种方式最合适?不同的传递方式有什么区别?在具体应用中应如何选择?
下面的例子将比较这三种在函数间传递数据的方式,帮助我们理解如何做出最佳选择:
#include <iostream>
using namespace std;
// 通过传值来传入参数和传出返回值
int FuncByValue(int x)
{
x = x + 1;
return x;
}
// 通过传指针来传入参数和传出返回值
int* FuncByPointer(int* p)
{
*p = *p + 1;
return p;
}
// 通过传引用来传入参数和传出返回值
int& FuncByRef(int& r)
{
r = r + 1;
return r;
}
int main()
{
int n = 0;
cout << "n的初始值,n = " << n << endl;
// 以传值方式调用函数,变量 n 的值不发生改变
FuncByValue(n);
cout << "传值,n = " << n << endl;
// 以传指针方式调用函数,实现数据的同时传入传出
// 变量 n 的值发生改变
FuncByPointer(&n);
cout << "传指针,n = " << n << endl;
// 以传引用方式调用函数,实现数据的同时传入传出
// 变量 n 的值发生改变
FuncByRef(n);
cout << "传引用,n = " << n << endl;
return 0;
}
编译并运行程序后,可以得到如下的输出结果:
n的初始值, n = 0
传值, n = 0
传指针, n = 1
传引用, n = 2
1) 在函数 FuncByValue() 中,形式参数 x 只是外部实际参数 n 的一份拷贝。函数内部对 x 的运算不能改变函数外部 n 的值,所以输出的 n 值仍然为 0,与初始值相同。
2) 在函数 FuncByPointer() 中,指针 p 指向外部变量 n,在函数内部改变指针 p 所指向的数据值,实际上就是改变函数外部变量 n 的值,所以输出的 n 值为 1。
3) 在函数 FuncByRef() 中,引用 r 与函数外部变量 n 相关联,它们实际上是同一个数据。在函数内部改变 r 的值,同样也会修改函数外部 n 的值,因此最终输出的 n 值为 2。
对比以上这三种传递参数的方式,可以发现:
- 传引用的性质与传指针相似,都是通过传递函数外部数据的某种指代来代替传递数据本身,既可以传入数据,也可以传出数据。
- 传引用的书写形式与传值相似,可以直接使用变量作为实际参数调用函数,函数内部引用的使用方式也与普通变量相同。这样,传引用既具备了传指针的高效和灵活性(节省空间,提高效率,适用于参数的传入和传出),同时又保持了与传值相同的书写形式,使得引用在函数中的使用更加简单自然,代码的可读性也更高。可以说,传引用同时具备了传指针和传值两者的优点。
综上所述,在传递小体积的参数时,例如某个 int 类型的数据,如果只需传入数据,则选择传值方式;如果需要同时传入和传出数据,则选择传引用方式。在传递大体积的参数时,例如大型对象,优先选择传引用方式。
三种传递参数的方式如下图所示。
图 1 优先选择传引用
 ICP备案:
ICP备案: 公安联网备案:
公安联网备案: