Neo4j APOC安装和使用教程(非常详细,新手必看)
APOC 的名字最早出现在 2009 年,英文全称为A Package of Components,表示 Neo4j 的组件库,后来变为 Awesome Procedures on Cypher,意为超级棒的 Cypher 过程。
APOC 是用 Java 实现的,由 450+ 个过程和函数组成(目前还在不断更新中),用于完成数据集成、图形算法、数据转换等领域的不同任务。
与电影《黑客帝国》中情节不同的是,在 Neo4j 中,APOC 提供的过程极大地增强了 Cypher 的表达能力。
APOC 的安装步骤如下:
1) 下载APOC安装包。Neo4j 的 APOC 手册中有 APOC 安装包的下载地址,读者可以通过该地址下载适配的版本。笔者选用的安装包是 apoc-3.5.0.11-all.jar。
2) 安装APOC。将第 1 步下载的 jar 文件复制到 Neo4j 的 plugins 目录下。在 Windows 环境下,plugins 目录的路径为 D∶\neo4j-community-3.5.5\plugins;在 Ubuntu 环境下,plugins 目录的路径为 /var/lib/neo4j/plugins。
3) 修改配置文件。在 neo4j.conf 配置文件中添加以下内容:
4) 重启 Neo4j 服务。
5) 在可视化界面运行以下代码:
相比于过程,函数更易于理解。函数可以直接应用在 Cypher查询中,对传入的数据进行计算并返回计算后的结果,这点与 Cypher 内置的函数没有明显区别。
过程的调用必须使用 Call 命令,APOC 中的过程可以类比于关系数据库中的存储过程。
APOC 的常见功能如下:
这些过程大多位于 apoc.load 包下,也有部分位于 apoc.import 包、apoc.mongodb 包、apoc.es 包下。
APOC 支持导出的过程大多位于 apoc.export 包下。在将数据导出到文件系统中时可能会出现权限问题,这时可以通过在 neo4j.conf 文件中设置以下属性来启用权限:
如果没有设置为上述代码,在执行导出操作时,将出现以下错误消息,其意为调用 apoc.export.csv.all 失败:
需要注意的是,如果启用 apoc.trigger 包,那么需要在 neo4j.conf 中启用,使用的代码如下:
全文索引的相关函数或过程位于 apoc.schema 包下。
如果要使用相关图算法,可使用 Neo4j 图算法库中的算法。路径查找算法主要位于 apoc.algo 包中。
得到的返回值为APOC支持的过程和函数,具体如下:
使用以下代码查看 APOC 支持的过程和函数的数量:
然后使用 APOC 生成随机图,代码如下:
最后查看所有路径,代码如下:
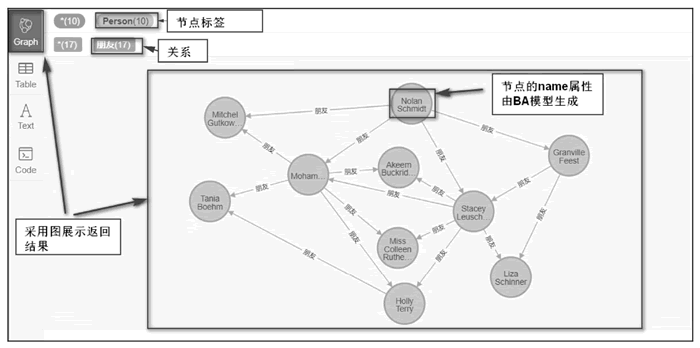
图 1 APOC 生成的随机图
首先,删除图中所有的节点和关系,代码如下:
其次,创建 1000 个节点,代码如下:
再次,创建 100 万个关系,代码如下:
最后,调用 PageRank 算法,计算 NodeLabel 节点中的重要性排名,代码如下:
上述代码的返回结果如下图所示:
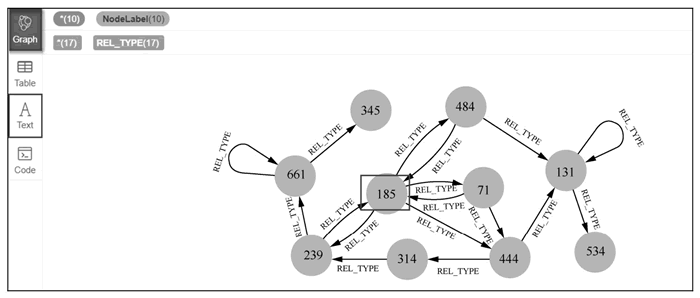
图 2 PageRank 算法的返回结果
从中可以看出 id 为 185 的节点的关系很多。在图 2 中,我们选择展示方式为“Text”,会看到 PageRank 算法计算的具体得分。
上述代码的返回值如下:
同样使用 APOC 将数据类型转换为字符串的操作,代码如下:
在 APOC 发布之前,开发人员需要为 Cypher 或 Neo4j 尚未实现的常用功能编写过程和函数。每个开发人员都可能编写所需的函数,这会导致出现大量的重复代码。针对这种需求,Neo4j 官方开发了一个过程和函数的标准库,即 APOC,在 Neo4j 3.3 版本中,APOC 成为 Neo4j 的标准库。有趣的是,在《黑客帝国》电影中,APOC 是 Neo 的队友,也是飞船的驾驶员,最终被叛徒 Cypher 杀害。
APOC 是用 Java 实现的,由 450+ 个过程和函数组成(目前还在不断更新中),用于完成数据集成、图形算法、数据转换等领域的不同任务。
与电影《黑客帝国》中情节不同的是,在 Neo4j 中,APOC 提供的过程极大地增强了 Cypher 的表达能力。
安装APOC
APOC 依赖于 Neo4j 的内部 API,其版本需要和 Neo4j 的版本相匹配。APOC 的安装步骤如下:
1) 下载APOC安装包。Neo4j 的 APOC 手册中有 APOC 安装包的下载地址,读者可以通过该地址下载适配的版本。笔者选用的安装包是 apoc-3.5.0.11-all.jar。
2) 安装APOC。将第 1 步下载的 jar 文件复制到 Neo4j 的 plugins 目录下。在 Windows 环境下,plugins 目录的路径为 D∶\neo4j-community-3.5.5\plugins;在 Ubuntu 环境下,plugins 目录的路径为 /var/lib/neo4j/plugins。
3) 修改配置文件。在 neo4j.conf 配置文件中添加以下内容:
dbms.security.procedures.unrestricted=apoc.*上述配置语句可以完成 APOC 的函数和过程授权。若不配置改行语句,则在执行函数和过程时,可能会出现错误:
apoc.algo.pagerank is not available due to having restricted success rights, check configuration意思是 apoc.algo.pagerank 具有受限的 scress 权限,故不可用,请检查配置。
4) 重启 Neo4j 服务。
5) 在可视化界面运行以下代码:
return apoc.version()得到的返回值如下:
│"apoc.version()"│ │"3.5.0.11" │可以看出,返回值中出现了对应的版本号,这说明安装成功。
APOC的使用
APOC 提供了数据集成、数据导出、数据结构、高级图查询等诸多功能,本小节将对部分过程和函数进行演示。相比于过程,函数更易于理解。函数可以直接应用在 Cypher查询中,对传入的数据进行计算并返回计算后的结果,这点与 Cypher 内置的函数没有明显区别。
过程的调用必须使用 Call 命令,APOC 中的过程可以类比于关系数据库中的存储过程。
1、APOC提供的过程和函数概述
APOC提供的过程与函数数量较多,在使用过程中若需要基于APOC实现,可以在官网手册中获得更详细的使用说明。读者在查看过程中,可以将APOC 3.5版本的官网手册和APOC 5.10版本的官网手册对比着阅读。APOC 的常见功能如下:
1) 数据集成
APOC 支持将各种数据格式(如 JSON、XML和XLS)导入到 Neo4j 中,也可以从关系数据库 MongoDB、Elasticsearch 中将数据导入到 Neo4j 数据库中。这些过程大多位于 apoc.load 包下,也有部分位于 apoc.import 包、apoc.mongodb 包、apoc.es 包下。
2) 数据导出
Neo4j 可以通过备份和导出命令来导出整个数据库,但不支持导出子图,或者将数据以标准数据格式导出。APOC 扩展了 Neo4j 的导出功能,使得 Neo4j 能够将数据导出为 JSON、CSV、GraphML、Cypher 脚本等格式。APOC 支持导出的过程大多位于 apoc.export 包下。在将数据导出到文件系统中时可能会出现权限问题,这时可以通过在 neo4j.conf 文件中设置以下属性来启用权限:
apoc.export.file.enabled=true
如果没有设置为上述代码,在执行导出操作时,将出现以下错误消息,其意为调用 apoc.export.csv.all 失败:
Failed to invoke procedure apoc.export.csv.all
3) 数据结构
APOC 提供用于操作数据结构的函数和过程。针对数据结构的操作主要分为 3 种,分别是转换功能、映射功能和集合功能:- 转换功能主要位于 apoc.convert 包中,用于强制转换值的类型;
- 映射功能位于 apoc.map 包中,用于对 map 类型数据进行操作;
- 集合功能主要位于 apoc.coll 包中,用于对集合和列表进行操作。
4) 时间格式操作
APOC 提供了对时间类型、时间戳和日期字符串进行格式化的函数,这些函数主要位于 apoc.temporal 包和 apoc.date 包中。5) 数学运算
APOC 提供关于数学运算的函数和过程,具体包括数学运算(如四舍五入、最大/最小值等)、精确计算、数字格式转换、位运算等:- 数学运算函数主要位于 apoc.math 包中;
- 精确计算函数位于 apoc.number.exact 包中;
- 数字格式转换函数位于 apoc.number 包中;
- 位运算操作位于 apoc.bitwise 包下。
6) 高级图查询
APOC 提供的高级图查询包含扩展路径、扩展子图、邻居功能、路径操作、关系查询、节点查询、并行节点搜索等,与之相关的函数或过程主要位于 apoc.path、apoc.neighbors、apoc.rel、apoc.nodes、apoc.search 等包中。7) 触发器
APOC 提供触发器,其功能类似于关系数据库中触发器的功能,可以在创建、更新或删除 Neo4j 中的数据时触发相关操作。与之相关的函数或过程主要位于 apoc.trigger 包中。需要注意的是,如果启用 apoc.trigger 包,那么需要在 neo4j.conf 中启用,使用的代码如下:
apoc.trigger.enabled=true
8) 文本和查找索引
从 3.5 版本开始,Neo4j 提供内置的、不区分大小写的、可配置的全文索引。原有的手工检索和全文检索(位于 apoc.index 包中)将逐渐被废弃。全文索引的相关函数或过程位于 apoc.schema 包下。
9) 图算法
在算法方面,APOC 提供路径查找算法。在图算法方面,Neo4j 提供了专用的图算法库 Graph Algorithms Library,目前 APOC 中除了路径查找算法外,其余算法将被弃用,即被删除。如果要使用相关图算法,可使用 Neo4j 图算法库中的算法。路径查找算法主要位于 apoc.algo 包中。
3、APOC应用
1) 帮助命令
使用以下代码查看 APOC 支持的过程和函数:
call apoc.help('apoc')
得到的返回值为APOC支持的过程和函数,具体如下:
1 "procedure" 2 "apoc.algo.aStar" 3 "apoc.algo.aStar(startNode, endNode, 'KNOWS|<WORKS_WITH|IS_MANAGER_OF>', 'distance','lat','lon') YIELD path, weight - run A* with relationship property name as cost function" 4 "apoc.algo.aStar(startNode :: NODE?, endNode :: NODE?, relationshipTypesAnd Directions :: STRING?, weightPropertyName :: STRING?, latPropertyName :: STRING?, lonPropertyName :: STRING?) :: (path :: PATH?, weight :: FLOAT?)" null null由于返回值较长,我们仅列出一条返回结果。为了分析返回结果,我们将返回结果进行分行。各行的含义如下:
- 第 1 行的 procedure 表示类型为过程。
- 第 2 行的 apoc.algo.aStar 表示过程的名称。
- 第 3 行表示该过程的一个应用案例。
- 第 4 行展示了过程的签名信息,签名的一般形式是 name::TYPE。在调用过程或函数时,通过签名可以获得对应参数的名称、类型及位置,同时还可获得返回值列的名称和类型。
使用以下代码查看 APOC 支持的过程和函数的数量:
CALL dbms.functions() YIELD name WHERE name STARTS WITH 'apoc.' RETURN COUNT(name) UNION CALL dbms.procedures() YIELD name WHERE name STARTS WITH 'apoc.' RETURN COUNT(name)得到的返回值为:
│"COUNT(name)"│ │246 │ │294 │这表示 3.5.0.11 版本的 APOC 包含了 246 个函数和 294 个过程。
2) 生成随机图
先删除图中所有的节点和关系,代码如下:MATCH (n) DETACH DELETE n
然后使用 APOC 生成随机图,代码如下:
CALL apoc.generate.ba(10,2,'Person','朋友')CALL apoc.generate.ba(10, 2, 'Person','朋友') 中的 ba 表示 Barabási–Albert 模型(BA 模型)。
最后查看所有路径,代码如下:
MATCH p = (n) - [r] - (m) RETURN p返回结果如下图所示:
图 1 APOC 生成的随机图
3) 基于PageRank算法实现节点排名
在 Google 搜索引擎中,PageRank 算法被用来计算网站的排名。PageRank 算法的规则是:关系越多,以及与重要节点的关系越多,则该节点越重要。首先,删除图中所有的节点和关系,代码如下:
MATCH (n) DETACH DELETE n
其次,创建 1000 个节点,代码如下:
FOREACH (id in range(1,1000) | CREATE (n:NodeLabel{id:id}))
再次,创建 100 万个关系,代码如下:
MATCH (n1:NodeLabel),(n2:NodeLabel) WITH n1,n2 LIMIT 1000000 WHERE rand()<0.1 CREATE (n1) - [:REL_TYPE]->(n2)
最后,调用 PageRank 算法,计算 NodeLabel 节点中的重要性排名,代码如下:
MATCH (n:NodeLabel) WITH collect(n) AS ns CALL apoc.algo.pageRank(ns) YIELD node,score RETURN node,score ORDER BY score DESC LIMIT 10在 ORDER BY 代码行中,我们添加了 LIMIT 10,这是为了防止出现返回值计算时间过长的情况。
上述代码的返回结果如下图所示:
图 2 PageRank 算法的返回结果
从中可以看出 id 为 185 的节点的关系很多。在图 2 中,我们选择展示方式为“Text”,会看到 PageRank 算法计算的具体得分。
4) APOC函数使用
APOC 的函数使用与 Cypher 的内置函数使用基本一致,下面使用 APOC 实现均值计算功能,代码如下:RETURN apoc.coll.avg([1,2,3,4,5]) AS output上述代码中的 apoc.coll.avg() 函数为 APOC 提供的函数。在使用过程中,我们只需要将参数放入函数中,便可得到返回值。
上述代码的返回值如下:
│"output"│ │3.0 │
同样使用 APOC 将数据类型转换为字符串的操作,代码如下:
RETURN apoc.convert.toStringList([1, "2", 3, "Four"]) AS output得到的返回值如下:
│"output" │ │["1","2","3","Four"]│可以看出,1 也用双引号包裹起来了,这表明其数据类型为字符串。
 ICP备案:
ICP备案: 公安联网备案:
公安联网备案: