PHP下载文件的2种实现方法(附带实例)
PHP 程序中,下载文件十分简单,建立一个链接指向目标文件即可,例如下述链接格式:
下面介绍两种文件下载方式:
1) Redirect 方式。先检查表格是否已经填写完毕和完整,然后将链接指向该文件,用户便可以下载文件了。示例代码如下:
2) 根据下载文件的 ID 来查找。链接的形式如下:
以上两种方式虽然实现了文件的下载功能,但缺点是直接暴露了文件所属路径,而且没有防盗链的功能,所以上述方式是简单、直接但存在安全隐患的文件下载方式。在 PHP 中,通常利用 header() 函数和 fread() 函数来实现安全的文件下载。
例如,需要下载一个文件名为“xxx.rar”的文件,首先创建名为“download.php”的 PHP 文件。前述例子可以很容易地通过文件的 ID 从数据库中得到待下载文件的真实存储位置,之后可以通过 header() 函数的 location 参数直接重定向到这个文件。
但是这样仍然是不安全的,因为某些下载软件还是可以通过重定向分析获得该文件的存储位置信息,因此,需要使用另外一种方法,即使用 PHP 文件处理 API 函数。它通过 fread() 函数直接将文件输出到浏览器,提示用户下载,这样所有的处理都是在服务器上完成的,因而用户无法获得文件的具体存储位置信息。
客户端从服务器下载文件的流程具体如下:
注意任何有关从服务器下载文件的操作,必须先在服务器将文件读入内存,再从内存中读取文件,通过使用 fread() 函数完成该操作。
需要注意的是,如果文件较大,文件会被分成多个片段返回客户端(浏览器),而不是等文件在服务器上全部读取完毕,一次性返回客户端,因为这会增加服务器的负荷,因此在 PHP 代码中需要设置一次读取的字节数,如在下面的实例中通过“$buffer = 1024”设置了一次读取的字节数。
down.php 的执行流程如下图所示:
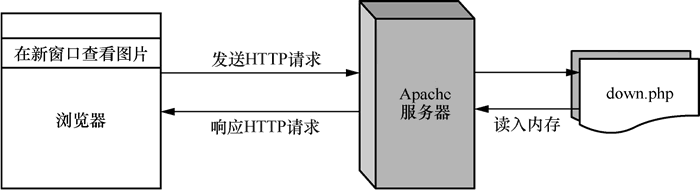
图 1 down.php的执行流程
【实例 1】下载文件。
图 2 运行结果
从运行结果中可以看到文件按照预想的方式被提示下载,接下来可单击“保存”按钮将文件保存在本地。
在上述代码中,程序发送 header 信息用于告诉 Apache 服务器和浏览器下载文件的相关信息,Content-Type 的含义为文件 MIME 类型是文件流格式。关于 file_exists() 函数不支持中文路径的问题,因为 PHP 函数出现较早,不支持中文,所以如果被下载的文件的文件名是中文,需要对其进行字符编码转换,否则 file_exists() 函数将不能识别该文件。
header("Content-Type: application/octet-stream") 的作用是让浏览器知道服务器返回文件的形式。
header("Accept-Ranges: bytes") 的作用是告诉浏览器返回文件的大小是按照字节进行计算的。
header("Accept-Length:".$file_size) 的作用是告诉浏览器返回文件的大小。
header("Content-Disposition: attachment; filename=".$file_name) 的作用是告诉浏览器返回文件的名称。
以上 4 个 header() 函数是必要的,fclose($fp) 可以把缓冲区内最后剩余的数据输出到磁盘文件中,并释放文件指针和有关的缓冲区。
<a href=http://www.xxx.com/xxx.rar>单击下载文件</a>但是,实际情况可能会更加复杂,例如浏览器重定下载、文件查找下载、用户登录后下载等。
下面介绍两种文件下载方式:
1) Redirect 方式。先检查表格是否已经填写完毕和完整,然后将链接指向该文件,用户便可以下载文件了。示例代码如下:
<?php
/*文件功能:检查变量form是否完整*/
if($form){
//重新定向浏览器指向
header("location: http:// http://www.xxx.com/xxx.rar");
exit;
}
?>
2) 根据下载文件的 ID 来查找。链接的形式如下:
<a href="http://www.xxx.com/download.php?id=123455">单击下载文件</a>上述链接使用 ID 方式接收要下载文件的 ID,然后采用 Redirect 方式连接到真实的文件链接。
以上两种方式虽然实现了文件的下载功能,但缺点是直接暴露了文件所属路径,而且没有防盗链的功能,所以上述方式是简单、直接但存在安全隐患的文件下载方式。在 PHP 中,通常利用 header() 函数和 fread() 函数来实现安全的文件下载。
例如,需要下载一个文件名为“xxx.rar”的文件,首先创建名为“download.php”的 PHP 文件。前述例子可以很容易地通过文件的 ID 从数据库中得到待下载文件的真实存储位置,之后可以通过 header() 函数的 location 参数直接重定向到这个文件。
但是这样仍然是不安全的,因为某些下载软件还是可以通过重定向分析获得该文件的存储位置信息,因此,需要使用另外一种方法,即使用 PHP 文件处理 API 函数。它通过 fread() 函数直接将文件输出到浏览器,提示用户下载,这样所有的处理都是在服务器上完成的,因而用户无法获得文件的具体存储位置信息。
客户端从服务器下载文件的流程具体如下:
- 首先,浏览器发送一个请求,请求访问服务器中的某个网页(如:“down.php”);
- 然后,服务器在接收到该请求以后,马上运行“down.php”文件;
- 最后,在运行该文件时,必然要把下载的文件读入内存,通过使用 fopen() 函数完成该操作。
注意任何有关从服务器下载文件的操作,必须先在服务器将文件读入内存,再从内存中读取文件,通过使用 fread() 函数完成该操作。
需要注意的是,如果文件较大,文件会被分成多个片段返回客户端(浏览器),而不是等文件在服务器上全部读取完毕,一次性返回客户端,因为这会增加服务器的负荷,因此在 PHP 代码中需要设置一次读取的字节数,如在下面的实例中通过“$buffer = 1024”设置了一次读取的字节数。
down.php 的执行流程如下图所示:
图 1 down.php的执行流程
【实例 1】下载文件。
<?php
header("Content-Type:text/html;charset=utf-8");
// 用于解决中文无法显示的问题
// $file_name = iconv("utf-8", "gb2312", $file_name);
// $file_name = "cookie.jpg";
$file_name = "test.tar.gz";
// $file_sub_path = $_SERVER['DOCUMENT_ROOT'] . "marcofly/phpstudy/down/down/";
$file_sub_path = "upload/";
$file_path = $file_sub_path . $file_name;
echo $file_path;
// 首先要判断给定的文件是否存在
if (!file_exists($file_path)) {
echo "没有该文件";
return;
}
$fp = fopen($file_path, "r");
$file_size = filesize($file_path);
// 下载文件需要用到的头
header("Content-Type: application/octet-stream");
header("Accept-Ranges: bytes");
header("Accept-Length:" . $file_size);
header("Content-Disposition: attachment; filename=" . $file_name);
$buffer = 1024;
$file_count = 0;
// 向浏览器返回数据
while (!feof($fp) && $file_count < $file_size) {
$file_con = fread($fp, $buffer);
$file_count += $buffer;
echo $file_con;
}
fclose($fp);
?>
运行结果如下图所示:图 2 运行结果
从运行结果中可以看到文件按照预想的方式被提示下载,接下来可单击“保存”按钮将文件保存在本地。
在上述代码中,程序发送 header 信息用于告诉 Apache 服务器和浏览器下载文件的相关信息,Content-Type 的含义为文件 MIME 类型是文件流格式。关于 file_exists() 函数不支持中文路径的问题,因为 PHP 函数出现较早,不支持中文,所以如果被下载的文件的文件名是中文,需要对其进行字符编码转换,否则 file_exists() 函数将不能识别该文件。
header("Content-Type: application/octet-stream") 的作用是让浏览器知道服务器返回文件的形式。
header("Accept-Ranges: bytes") 的作用是告诉浏览器返回文件的大小是按照字节进行计算的。
header("Accept-Length:".$file_size) 的作用是告诉浏览器返回文件的大小。
header("Content-Disposition: attachment; filename=".$file_name) 的作用是告诉浏览器返回文件的名称。
以上 4 个 header() 函数是必要的,fclose($fp) 可以把缓冲区内最后剩余的数据输出到磁盘文件中,并释放文件指针和有关的缓冲区。
 ICP备案:
ICP备案: 公安联网备案:
公安联网备案: