Redis是什么,Redis数据库简介(新手必看)
目前企业中最流行的数据库模型主要有两种,分别是关系型数据库和非关系型数据库。典型的关系型数据库有 MySQL 和 MariaDB,而本节介绍的 Redis 就是一款常用的非关系型数据库。
有读者可能会问,既然都学了关系型数据库了,还有学习非关系型数据库的必要吗?一般来说,存储数据使用关系型数据库就够了,但是对于高并发、高性能的环境,关系型数据库的处理还有所欠缺,有需求空缺就会有市场产品来填补,非关系型数据库就是这样应运而生的。
非关系型数据库也被称为 NoSQL 数据库,NoSQL 的含义最初表示为“Non-SQL”,后来有人转解为“Not only SQL”。
2009年,在亚特兰大举行过一场“no:sql(east)”的讨论会,在这场讨论会上提出的口号叫“select fun,profit from real_world where relational=false”。因此,对 NoSQL 最普遍的解释是“非关联型的”,强调的是键值存储和面向文档数据库的优点,是传统关系型数据库的一个有效补充,而不是反对关系型数据库。
非关系型数据库经过多年的发展已经出现了很多种类,常见的有以下几种:
远程字典服务(Remote Dictionary Server,Redis)是意大利人 Salvatore Sanfilippo 使用 C语言编写开发的,为保证效率,它将数据以键值对的形式缓存在内存中,所以又称为缓存数据库。
Redis 之所以应用这么广泛,除了免费开源,还因为它具备以下特性:
为了存储不同类型的数据(Value),Redis 提供了以下 5 种基本数据结构:
Redis 的应用场景有很多,但应用最广泛的是在数据缓存(提高访问速度)系统方面。
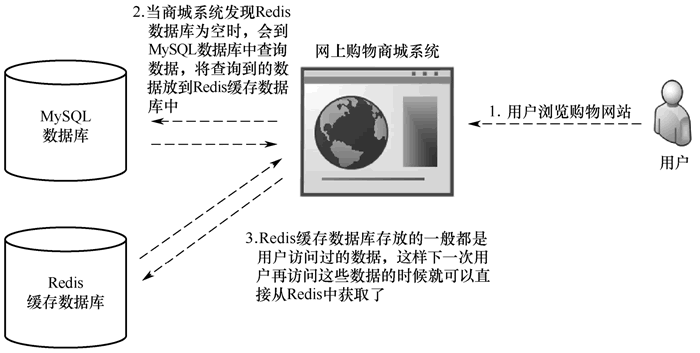
图 1 Redis在数据缓存系统中的应用
由上图可见,数据缓存系统会将一些在短时间内不发生变化,且会被频繁访问的数据(或者需要耗费大量资源生成的内容)放到 Redis 缓存数据库中,这样就可以让应用程序能够快速高效地读取它们。
在图 1 中,假如没有 Redis 缓存数据库,商城系统会直接去 MySQL 数据库中查询数据,并将结果返回用户。增加 Redis 缓存数据库后,查询数据的流程就变了,商城系统会先去 Redis 缓存数据库中查找数据,若没有,再去 MySQL 数据库中查询,查询到结果后会在 Redis 中存一份,下一次就可以直接从 Redis 中获取了。
因为 Redis 是直接将数据存储在内存中,而 MySQL 是将数据存储在硬盘中,相对而言,操作内存中的数据要比操作硬盘中的数据快。究竟有多快呢,举例说明:
通过数据的对比,大家应该能想象到内存的读写速度有多快,这也是 Redis 缓存数据库被广泛应用于各大企业运维架构的原因,只要将那些被频繁访问的数据存储到 Redis 缓存数据库中,就能大幅提高用户访问速度,降低网站的负载和 MySQL/MariaDB 数据库的读取频率。
Redis 将数据全部存储在内存中,这样虽然大大提高了处理数据的速度,但也会带来安全性问题,一旦 Redis服务器发生意外情况,例如突然宕机或断电等,内存中的数据将会全部丢失。因此必须有一种方案能够保证 Redis 储存的数据不会因为突发状况导致丢失,这就是 Redis 的数据持久化存储机制,数据的持久化存储是 Redis 的重要特性之一。
Redis 的持久化存储功能可以将内存中的数据以文件形式保存在硬盘中,用来避免发生突发状况导致数据丢失。当 Redis 服务重启时,就可以利用之前持久化存储的文件恢复数据。
有读者可能会问,既然都学了关系型数据库了,还有学习非关系型数据库的必要吗?一般来说,存储数据使用关系型数据库就够了,但是对于高并发、高性能的环境,关系型数据库的处理还有所欠缺,有需求空缺就会有市场产品来填补,非关系型数据库就是这样应运而生的。
非关系型数据库也被称为 NoSQL 数据库,NoSQL 的含义最初表示为“Non-SQL”,后来有人转解为“Not only SQL”。
2009年,在亚特兰大举行过一场“no:sql(east)”的讨论会,在这场讨论会上提出的口号叫“select fun,profit from real_world where relational=false”。因此,对 NoSQL 最普遍的解释是“非关联型的”,强调的是键值存储和面向文档数据库的优点,是传统关系型数据库的一个有效补充,而不是反对关系型数据库。
非关系型数据库经过多年的发展已经出现了很多种类,常见的有以下几种:
- 键值(Key-Value)存储:每个单独的项都存储为键值对,可以通过 key 值快速查询到其 value 值。键值存储是所有NoSQL数据库中最简单的数据库,也是在缓存系统中应用范围最广的。代表产品有 Redis、MemcacheDB 等;
- 文档(Document-Oriented)存储:旨在将半结构化数据存储为文档,文档包括 XML、YAML、JSON、BSON、Office 文档等。代表产品有 MongoDB、Apache CouchDB 等;
- 列(Column-oriedted)存储:以列簇的方式存储,将同一列数据存在一起,查找速度快,可扩展性强,更容易进行分布式扩展。代表产品有 Hbase、Cassandra 等;
- 图形(Graph)存储:将数据以图的方式储存,是图形关系的最佳存储方案。代表产品有 Neo4J、FlockDB 等。
远程字典服务(Remote Dictionary Server,Redis)是意大利人 Salvatore Sanfilippo 使用 C语言编写开发的,为保证效率,它将数据以键值对的形式缓存在内存中,所以又称为缓存数据库。
Redis 之所以应用这么广泛,除了免费开源,还因为它具备以下特性:
- 基于内存实现数据存储,读写速度超级快,测试数据显示它的读取速度约为 110000次/s,写速度约为 81000次/s;
- 支持通过硬盘实现数据的持久存储;
- 支持丰富的数据类型;
- 支持主从同步,即 Master-Slave 主从复制模式;
- 支持多种编程语言。
为了存储不同类型的数据(Value),Redis 提供了以下 5 种基本数据结构:
- 字符串(String):Redis 最基本的数据类型,是二进制安全的字符串,意味着不仅能够存储字符串,还可以包含任何数据,例如图片或者序列化的对象等,一个字符串类型的值最多能够存储 512MB 大小的数据;
- 哈希散列(Hash):一个键值对的集合,可以理解为由 string 类型的 key 值和 value 值组成的映射表,key 值就是 key 值本身,但 value 值却是一个键值对(Key-Value);
- 链表(List):底层实际上是个链表,可以按照插入顺序进行排序,例如添加一个元素到列表的头部或者尾部,其特点是有序且可以重复;
- 集合(Set):String 类型的无序集合,其特点是无序且不可重复;
- 有序集合(Zset):和 Set 类型一样,也是 String 类型的集合,但它是有序的。
Redis 的应用场景有很多,但应用最广泛的是在数据缓存(提高访问速度)系统方面。
图 1 Redis在数据缓存系统中的应用
由上图可见,数据缓存系统会将一些在短时间内不发生变化,且会被频繁访问的数据(或者需要耗费大量资源生成的内容)放到 Redis 缓存数据库中,这样就可以让应用程序能够快速高效地读取它们。
在图 1 中,假如没有 Redis 缓存数据库,商城系统会直接去 MySQL 数据库中查询数据,并将结果返回用户。增加 Redis 缓存数据库后,查询数据的流程就变了,商城系统会先去 Redis 缓存数据库中查找数据,若没有,再去 MySQL 数据库中查询,查询到结果后会在 Redis 中存一份,下一次就可以直接从 Redis 中获取了。
因为 Redis 是直接将数据存储在内存中,而 MySQL 是将数据存储在硬盘中,相对而言,操作内存中的数据要比操作硬盘中的数据快。究竟有多快呢,举例说明:
- 固态硬盘读写速度大概是 300MB/s;
- 机械硬盘读写速度大概是 100MB/s;
- DDR4 内存的读写速度大约 50GB/s。
通过数据的对比,大家应该能想象到内存的读写速度有多快,这也是 Redis 缓存数据库被广泛应用于各大企业运维架构的原因,只要将那些被频繁访问的数据存储到 Redis 缓存数据库中,就能大幅提高用户访问速度,降低网站的负载和 MySQL/MariaDB 数据库的读取频率。
Redis 将数据全部存储在内存中,这样虽然大大提高了处理数据的速度,但也会带来安全性问题,一旦 Redis服务器发生意外情况,例如突然宕机或断电等,内存中的数据将会全部丢失。因此必须有一种方案能够保证 Redis 储存的数据不会因为突发状况导致丢失,这就是 Redis 的数据持久化存储机制,数据的持久化存储是 Redis 的重要特性之一。
Redis 的持久化存储功能可以将内存中的数据以文件形式保存在硬盘中,用来避免发生突发状况导致数据丢失。当 Redis 服务重启时,就可以利用之前持久化存储的文件恢复数据。
 ICP备案:
ICP备案: 公安联网备案:
公安联网备案: