C++类的定义和使用(非常详细)
面向对象程序设计将现实世界中的所有事物视为对象,而类则是对所有相同类型对象的抽象,是对它们共同特征的描述。
例如,在一所学校中,有张老师、李老师、王老师等多位老师。尽管每位老师都有自己独特的特点,作为不同的对象个体存在,但他们都属于“老师”这一类型的对象。他们拥有一些共同的属性,例如姓名和职务,以及一些相同的行为,如上课和批改作业。
在面向对象程序设计中,我们把某一类型对象的共同属性和行为抽象出来。属性用变量描述,行为用函数(或称为方法)描述。然后,我们将这些变量和函数封装在一个类中,这样就创建了一个新的数据类型,可以用来描述这一类型的对象。这种新的数据类型就是类,它定义了创建对象的蓝图。
在 C++ 中,定义一个类的语法格式如下:
C++ 中的类还有基类与派生类之分,这是面向对象程序设计中继承机制在类中的体现。如果这个类是从某个基类继承而来的,我们在“class类名”后面还要加上这个类的继承方式(public、protected 或 private)以及它所继承的基类的名字。这样,定义一个类的语法格式相应地变为:
完成类的名字及继承关系的定义后,就可以在类的主体中描述这个类的属性和行为了。
对象的属性属于数据,因此我们在类中定义一些变量来描述对象的属性。例如,“老师”这一类对象拥有姓名这个属性,所以我们可以定义一个 string 类型的变量 strName 来描述。这些变量描述了对象的属性,成为这个类整体的一部分,因此也被称为成员变量。
例如:
经过这样的定义,在创建这个类的对象时,无须在构造函数中进行额外的初始化,这两个成员变量将自动拥有相应的初始值。这一特性可以用于所有类的对象都具有相同初始值的情况,例如所有 Teacher 对象的 m_unSalary(工资)都是 2000 元。
除声明成员变量来描述对象的属性外,对象的另一个重要组成部分就是它的行为。在 C++ 中,我们用函数来描述一个行为(或动作、操作)。我们将函数引入类中成为它的成员函数,用来描述类对象的行为。
例如,一个“老师”对象有备课的行为,我们可以为老师这个类添加一个 PrepareLesson() 函数,在这个函数中对老师的备课行为进行定义。
类的构成如下图所示:
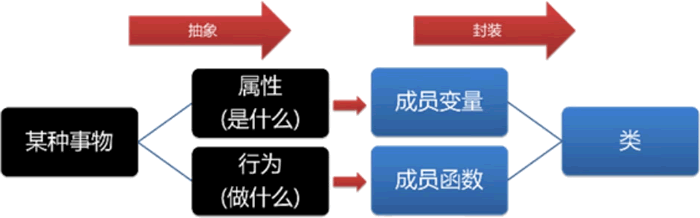
按照访问级别的不同,类的所有成员被分为三个部分:
这里先来看一个实际例子。例如,要定义一个类来描述“老师”这一类对象,通过对这类对象的抽象,我们发现老师这一类拥有只有自己和子类可以访问的姓名属性,以及大家都可以访问的上课行为。当然,老师还有很多其他属性和行为,这里为了简化问题,我们仅展示核心部分。通过面向对象的封装机制,我们可以将这些属性和行为捆绑到一起,从而定义出“老师”这个类。
这样,通过在类中声明函数来描述对象的行为,声明变量来描述对象的属性,我们就完整地定义了一个用于描述某类对象的类。
完成类的定义之后,我们还需要对类的行为进行定义。类成员函数的具体定义可以直接在类中声明成员函数的同时完成:
class 和 struct 非常相似,两者都可以用来定义类,它们唯一的区别在于,默认的访问级别不同,用 class 声明的类中的成员默认是私有的(private),而用 struct 声明的类中的成员默认是公有的(public)。例如:
例如:
class 和 struct 除在类成员默认访问级别上的差异外,从直觉上讲,大多数程序员认为它们仍有差异:struct 通常为视为一堆缺乏封装的开放内存位,更多时候用于表示比较复杂的数据;而 class 更像活的、可靠的现实实体,它可以提供服务,并具有牢固的封装机制和定义良好的接口。
基于这种直觉,当类只有少数成员函数且有较多公有数据时,可以考虑使用 struct 关键字;在其他情况下,使用 class 关键字可能更为合适。
例如,前面完成了 Teacher 类的定义,可以用它创建一个 Teacher 类的对象,用来表示某一位具体的老师。创建类的对象的方式与定义变量的方式相似,只需将定义完成的类当作一种数据类型,像定义变量一样定义对象,而定义得到的变量就是这个类的对象。其语法格式如下:
除直接使用对象外,像普通的数据类型可以使用相应类型的指针来访问它所指向的数据一样,对于自己定义的类,我们同样可以把它当作数据类型来定义指针,把它指向某个具体的对象,进而通过指针来访问该对象的成员。例如:
除可以使用“&”操作符取得已有对象的地址,并将这个地址赋值给指针使之指向某个对象外,还可以使用 new 关键字直接创建一个对象,并返回该对象的地址,再把这个地址赋值给指针,同样可以创建新的对象并将指针指向这个新的对象。例如:
有了指向对象的指针,就可以利用“->”操作符(这个操作符是不是很像一根针?)通过指针访问该对象的公有成员。例如:
当对象被销毁后,原来指向这个对象的指针就成了一个指向无效地址的“野指针”。为了防止这个“野指针”被错误地再次使用,我们通常在用 delete 关键字销毁对象后,紧接着将这个指针赋值为 nullptr,使其成为一个空指针,以避免再次使用它。
很多有经验的 C++ 程序员都会强调,为了提高代码的健壮性,我们在使用指针之前,应该先检查指针是否为 nullptr,确定其有效之后才能使用。在使用指针访问类的成员时,这样的检查是必要的。然而,如果是在使用 new 创建对象之后和 delete 销毁对象之前进行检查,则完全是画蛇添足。
一方面,使用 new 关键字创建新对象时,如果系统无法为新对象分配足够的内存而导致创建对象失败,则会抛出一个 std::bad_alloc 异常,而不会返回 nullptr。另一方面,C++ 语言也保证,如果指针 p 的值是 nullptr,则 delete p 不作执行任何操作,自然也不会发生任何错误。
因此,在使用 new 关键字创建对象之后和使用 delete 关键字销毁对象之前,都无须检查指针的有效性,直接使用即可。
例如,在一所学校中,有张老师、李老师、王老师等多位老师。尽管每位老师都有自己独特的特点,作为不同的对象个体存在,但他们都属于“老师”这一类型的对象。他们拥有一些共同的属性,例如姓名和职务,以及一些相同的行为,如上课和批改作业。
在面向对象程序设计中,我们把某一类型对象的共同属性和行为抽象出来。属性用变量描述,行为用函数(或称为方法)描述。然后,我们将这些变量和函数封装在一个类中,这样就创建了一个新的数据类型,可以用来描述这一类型的对象。这种新的数据类型就是类,它定义了创建对象的蓝图。
在 C++ 中,定义一个类的语法格式如下:
class 类名
{
public:
// 公有成员,通常用于定义可以被类的外部直接访问的属性和方法(即函数)
protected:
// 受保护成员,仅对类及其派生类可见,不对外部代码公开
private:
// 私有成员,通常用于定义只能在类内部访问的属性和方法
}; // 注意这里有个分号,表示类的结束
其中,class 是 C++ 中用于定义类的关键字,其后是所要声明的类的名字,通常是某个可以概括这一类对象的名词。这里,我们要定义一个类来描述“老师”这类对象,因此我们用 Teacher 作为这个类的名字。C++ 中的类还有基类与派生类之分,这是面向对象程序设计中继承机制在类中的体现。如果这个类是从某个基类继承而来的,我们在“class类名”后面还要加上这个类的继承方式(public、protected 或 private)以及它所继承的基类的名字。这样,定义一个类的语法格式相应地变为:
class 类名 : 继承方式 基类名
{
// 成员变量和成员函数的声明
};
如果某个类没有继承关系,则类声明中的继承方式可以省略。这里的 Teacher 类本身就是基类,并不是由其他类继承而来的,所以这里继承方式应当省略。完成类的名字及继承关系的定义后,就可以在类的主体中描述这个类的属性和行为了。
对象的属性属于数据,因此我们在类中定义一些变量来描述对象的属性。例如,“老师”这一类对象拥有姓名这个属性,所以我们可以定义一个 string 类型的变量 strName 来描述。这些变量描述了对象的属性,成为这个类整体的一部分,因此也被称为成员变量。
在类中给成员变量赋初始值
如果类的某些成员变量具有初始值,我们可以在类中声明这些成员变量的同时给它们赋初始值。这样在运行期间,类就在进入构造函数之前,就可以直接使用这些初始值来初始化相应的成员变量。例如:
class Teacher
{
// 具有初始值的成员变量
protected:
// 用字符串常量“Name”作为成员变量 m_strName 的初始值
string m_strName = "Name"; // 姓名
private:
// 用常数2000作为成员变量 m_unBaseSalary 的初始值
unsigned int m_unSalary = 2000;
};
在这段代码中,我们用两个常量分别作为类的两个成员变量 m_strName 和 m_unSalary 的初始值。经过这样的定义,在创建这个类的对象时,无须在构造函数中进行额外的初始化,这两个成员变量将自动拥有相应的初始值。这一特性可以用于所有类的对象都具有相同初始值的情况,例如所有 Teacher 对象的 m_unSalary(工资)都是 2000 元。
除声明成员变量来描述对象的属性外,对象的另一个重要组成部分就是它的行为。在 C++ 中,我们用函数来描述一个行为(或动作、操作)。我们将函数引入类中成为它的成员函数,用来描述类对象的行为。
例如,一个“老师”对象有备课的行为,我们可以为老师这个类添加一个 PrepareLesson() 函数,在这个函数中对老师的备课行为进行定义。
类的构成如下图所示:
类成员的访问权限
除在类中定义变量和函数来表示类的属性和行为外,还可以使用 public、protected 及 private 这三个关键字来对修饰这些成员,以指定它们的访问级别。按照访问级别的不同,类的所有成员被分为三个部分:
- 使用 public 修饰的成员,类的外部可见(即可以访问),我们会在 public 部分定义类的行为,提供公有函数的接口供外部访问;
- 使用 protected 修饰的成员只有类自己和它的派生类可以访问,因此在 protected 部分,我们可以定义“继承”给下一代子类的属性和行为;
- 使用 private 修饰的成员只有类自己可以访问,所以在 private 部分,我们可以定义这个类私有的属性和行为。
这里先来看一个实际例子。例如,要定义一个类来描述“老师”这一类对象,通过对这类对象的抽象,我们发现老师这一类拥有只有自己和子类可以访问的姓名属性,以及大家都可以访问的上课行为。当然,老师还有很多其他属性和行为,这里为了简化问题,我们仅展示核心部分。通过面向对象的封装机制,我们可以将这些属性和行为捆绑到一起,从而定义出“老师”这个类。
// 老师
class Teacher
{
// 成员函数
// 描述对象的行为
public: // 公有部分,供外界访问
void GiveLesson(); // 上课
// 成员变量
// 描述对象的属性
protected: // 受保护部分,自己和子类可以访问
string m_strName; // 姓名
private:
};
通过这段代码,我们定义了一个 Teacher 类,它是所有老师这种对象的一个抽象描述。这个类有一个 public关键字修饰的成员函数 GiveLesson(),代表老师这类对象拥有大家都可以访问的行为—上课。它还有一个 protected 关键字修饰的变量 m_strName,表示老师这类对象拥有只有自己和子类可以访问的属性—姓名。这样,通过在类中声明函数来描述对象的行为,声明变量来描述对象的属性,我们就完整地定义了一个用于描述某类对象的类。
完成类的定义之后,我们还需要对类的行为进行定义。类成员函数的具体定义可以直接在类中声明成员函数的同时完成:
class Teacher
{
// 成员函数
// 描述对象的行为
public:
// 声明成员函数的同时完成其定义
void GiveLesson()
{
cout << "老师上课。" << endl;
}
// ...
};
更多时候,我们会将类的定义放在头文件(例如 Teacher.h 文件)中,而将成员函数的具体实现放在类的外部定义,也就是相应的源文件(例如 Teacher.cpp)中。在类的外部定义类的成员函数时,我们需要在源文件中包含类声明所在的头文件,并且在函数名之前还要用“::”域操作符指出这个函数所属的类。例如:
// Teacher.h类的定义文件
#ifndef _TEACHER_H_ // 定义头文件宏,防止头文件被重复包含
#define _TEACHER_H_ // 在稍后的7.3.1节中会有详细介绍
class Teacher
{
// ...
public:
void GiveLesson(); // 只声明,不定义
};
#endif
// Teacher.cpp类的定义文件
// 包含类声明所在的头文件
#include "Teacher.h"
// 在Teacher类外完成成员函数的定义
void Teacher::GiveLesson()
{
cout << "老师上课。" << endl;
}
在这里,我们可以看到,成员函数的定义与普通函数并无二致,它们都是用来完成某个动作的。不同之处在于,成员函数所表示的是某类对象的行为(即动作)。例如,这里输出一个字符串表示老师上课的动作。当然,在实际应用中,类成员函数还可以对成员变量进行访问,并且所完成的动作也要复杂得多。C++ struct定义类
在 C++ 中,要定义一个类,除使用 class 关键字外,用于定义结构体的 struct 关键字也可以用来定义类。class 和 struct 非常相似,两者都可以用来定义类,它们唯一的区别在于,默认的访问级别不同,用 class 声明的类中的成员默认是私有的(private),而用 struct 声明的类中的成员默认是公有的(public)。例如:
// 使用 struct 定义一个 Rect 类
struct Rect
{
// 没有访问权限说明
// 类的成员函数,默认情况下是公有的(public)
int GetArea()
{
return m_nW * m_nH;
}
// 类的成员变量,默认情况下也是公有的(public)
int m_nW;
int m_nH;
};
在这里,我们使用 struct 声明了一个 Rect 类。因为没有使用 public 等关键字显式地指明类成员的访问控制,在默认情况下,类成员都是公有的,所以可以直接访问它们。例如:
Rect rect; // 直接访问成员变量 rect.m_nH = 3; rect.m_nW = 4; // 直接访问成员函数 cout << "Rect 的面积是:" << rect.GetArea() << endl;这两个关键字的默认访问控制要么过于保守,要么过于开放,这种“一刀切”的方式显然无法满足所有情况。因此,无论是使用 class 还是 struct 声明一个类,我们都应该在声明中明确指出适合各个成员的访问级别,而不应依赖于关键字的默认行为。
class 和 struct 除在类成员默认访问级别上的差异外,从直觉上讲,大多数程序员认为它们仍有差异:struct 通常为视为一堆缺乏封装的开放内存位,更多时候用于表示比较复杂的数据;而 class 更像活的、可靠的现实实体,它可以提供服务,并具有牢固的封装机制和定义良好的接口。
基于这种直觉,当类只有少数成员函数且有较多公有数据时,可以考虑使用 struct 关键字;在其他情况下,使用 class 关键字可能更为合适。
使用类创建对象
定义好一个类,并且也定义好所有的成员函数之后,这个类就可以使用了。一个定义完成的类相当于一种新的数据类型,我们可以用它来定义变量,也就是创建这个类所描述的对象,表示现实世界中的各种实体。例如,前面完成了 Teacher 类的定义,可以用它创建一个 Teacher 类的对象,用来表示某一位具体的老师。创建类的对象的方式与定义变量的方式相似,只需将定义完成的类当作一种数据类型,像定义变量一样定义对象,而定义得到的变量就是这个类的对象。其语法格式如下:
类名 对象名;
其中,类名是定义好的类的名字,对象名是要定义的对象的名字,例如:// 定义一个Teacher类的对象MrChen,代表陈老师 Teacher MrChen;这样就得到了一个 Teacher 类的对象 MrChen,用来表示学校中具体的某位陈老师。得到类的对象后,可以通过“.”操作符访问这个类提供的公有成员,包括读写其公有成员变量和调用其公有成员函数,从而访问其属性或者完成其动作。其语法格式如下:
对象名.公有成员变量; 对象名.公有成员函数();例如,要让刚才定义的对象 MrChen 进行“上课”的动作,可以通过“.”调用它的表示上课行为的成员函数:
// 调用对象所属类的成员函数,表示这位老师开始上课 MrChen.GiveLesson();这样,该对象就执行 Teacher 类中定义的 GiveLesson() 成员函数,完成上课的具体动作。
除直接使用对象外,像普通的数据类型可以使用相应类型的指针来访问它所指向的数据一样,对于自己定义的类,我们同样可以把它当作数据类型来定义指针,把它指向某个具体的对象,进而通过指针来访问该对象的成员。例如:
// 定义一个可以指向Teacher类型对象的指针pMrChen,并且初始化为空指针 Teacher* pMrChen = nullptr; // 用“&”操作符取得MrChen对象的地址并赋值给指针pMrChen // 也就是将pMrChen指针指向MrChen对象 pMrChen = &MrChen;在这里,我们首先把 Teacher 类当作数据类型,像使用普通数据类型一样定义了一个指向 Teacher 类型对象的指针 pMrChen,然后通过“&”取地址操作符取得 MrChen 对象的地址并赋值给 pMrChen 指针,这样该指针就指向了 MrChen 对象。
除可以使用“&”操作符取得已有对象的地址,并将这个地址赋值给指针使之指向某个对象外,还可以使用 new 关键字直接创建一个对象,并返回该对象的地址,再把这个地址赋值给指针,同样可以创建新的对象并将指针指向这个新的对象。例如:
// 创建一个新的Teacher对象 // 并让pMrChen指针指向这个新对象 Teacher* pMrChen = new Teacher();在这里,new 关键字会负责完成 Teacher 对象的创建,并返回这个对象的地址,然后将这个返回的对象地址赋值给 pMrChen 指针,这样就同时完成了对象的创建和指针的赋值。
有了指向对象的指针,就可以利用“->”操作符(这个操作符是不是很像一根针?)通过指针访问该对象的公有成员。例如:
// 通过指针访问对象的成员 pMrChen->GiveLesson();需要注意的是,与普通的变量不同,使用 new 关键字创建的对象在其生命周期结束后不会自动销毁,因此我们必须在对象使用完毕后,用 delete 关键字主动销毁这个对象,释放其占用的内存资源。例如:
// 销毁指针所指向的对象 delete pMrChen; pMrChen = nullptr; // 指向的对象销毁后,重新成为空指针delete 关键字首先会对 pMrChen 所指向的 Teacher 对象进行一些特有的清理工作,然后释放掉这个对象所占用的内存,整个对象也就销毁了。
当对象被销毁后,原来指向这个对象的指针就成了一个指向无效地址的“野指针”。为了防止这个“野指针”被错误地再次使用,我们通常在用 delete 关键字销毁对象后,紧接着将这个指针赋值为 nullptr,使其成为一个空指针,以避免再次使用它。
很多有经验的 C++ 程序员都会强调,为了提高代码的健壮性,我们在使用指针之前,应该先检查指针是否为 nullptr,确定其有效之后才能使用。在使用指针访问类的成员时,这样的检查是必要的。然而,如果是在使用 new 创建对象之后和 delete 销毁对象之前进行检查,则完全是画蛇添足。
一方面,使用 new 关键字创建新对象时,如果系统无法为新对象分配足够的内存而导致创建对象失败,则会抛出一个 std::bad_alloc 异常,而不会返回 nullptr。另一方面,C++ 语言也保证,如果指针 p 的值是 nullptr,则 delete p 不作执行任何操作,自然也不会发生任何错误。
因此,在使用 new 关键字创建对象之后和使用 delete 关键字销毁对象之前,都无须检查指针的有效性,直接使用即可。
// 创建对象 Teacher* p = new Teacher(); // 直接使用指针 p 访问对象 // 销毁对象 delete p; // 销毁对象之后,需要将指针赋值为 nullptr,避免“野指针”的出现 p = nullptr;
 ICP备案:
ICP备案: 公安联网备案:
公安联网备案: